

Dado el rápido crecimiento de tecnologías como redes sociales, computación en la nube o Cloud Computing, aplicaciones móviles y el ya más que famoso big data, es un momento lleno de desafíos para los arquitectos software que deben hacerse cargo de la inmensa cantidad de información producida cada segundo a nivel global y además a este escenario se le añade otro reto: los usuarios esperan que las aplicaciones estén siempre disponibles y que sean adaptables a todo ámbito. Para poder satisfacer dicha demanda necesitamos salirnos del modelo relacional de almacenamiento y empezar a utilizar las denominadas tecnologías NoSQL (Not only SQL) y entender la diferencia entre algunas de ellas, como Apache Solr vs Elasticsearch.
Estos sistemas se quitan de la necesidad de establecer toda la información en un único modelo relacional para acabar ajustando la información a lo que es cada una de ellas: un tipo de dato. Es decir, las tecnologías NoSQL están optimizadas para solventar un problema específico para tipos de datos específicos.
Los tiempos de un sistema único y grande que pueda con todo se han acabado, empiezan a imperar las arquitecturas hibridas compuestas de una variedad de bases de datos NoSQL y relacionales a la par.
¿Qué son los motores de búsqueda?
Dentro de las tecnologías NoSQL están los motores de búsqueda y es que ya sea para poder hacer frente al famoso big data, construir servicios basados en la nube o desarrollar aplicaciones web con alto tráfico, es vital tener un buscador rápido, fiable y optimizado.
Lucene (1999) se ha convertido en la base de dos de los mejores motores de búsqueda open source de nuestro tiempo: Solr (2004) y Elasticsearch (2010).
Lucene es una librería de recuperación de información. La definición de qué es recuperación de información podría ser la que dieron Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze en su artículo Introduction to Information Retrieval (Cambridge University Press, 2008)
La recuperación de información (Information retrieval, IR) consiste en encontrar material (generalmente documentos) de una naturaleza desestructurada (generalmente texto) que satisface una necesidad de información que se alberga en grandes colecciones (generalmente almacenada en ordenadores).
Lucene se encarga de construir y gestionar lo que se denomina índice invertido, una estructura de datos especializada en emparejar documentos de texto con términos de consulta. Las características principales de estos motores son:
- Escalables: capaces de distribuir el trabajo (indexación y procesado de consultas) a múltiples servidores en un cluster.
- Listo para ser desplegado: ambas soluciones vienen con ejemplos prácticos para levantar un servicio con el mínimo esfuerzo.
- Optimizados para búsquedas: son rápidos, muy rápidos, capaces de ejecutar consultas complejas en decenas de milisegundos.
- Grandes volúmenes de datos: están diseñados para lidiar con índices de billones de documentos.
- Centrados en texto: aunque soportan búsquedas sobre fechas y números, su base y principal fuerza es manejar textos naturales (correos, páginas web, artículos, documentos PDF y mensajes de redes sociales como blogs y tweets) extrayendo la estructura implícita del mismo al índice del motor para mejorar la búsqueda.
- Resultados ordenados por relevancia: dependiendo de la consulta del usuario se le devuelven documentos clasificados en base a dicha consulta.
Y la verdadera pregunta es… ¿Necesito un buscador?
Hay que pensar en si en los datos de tu sistema están centrados en texto, es decir si estos datos contienen información que tus usuarios vayan a querer consultar. Si es así, entonces definitivamente estos buscadores son tu solución.
Por ejemplo, si se tiene una base de datos (pongamos una base de datos con 20 millones de tuplas distribuidas en 5 tablas y un peso de 25Gb) realizar una consulta tan básica como conocer el numero de tuplas que existen vía SQL puede llegar a tardar más de 15 segundos. Esto es inviable y los propios índices del modelo relacional podrán ayudar en la ejecución, pero se seguirán quedando cortos. Aquí es necesaria la ayuda de estos sistemas de búsqueda si no queremos ver nuestra aplicación perjudicada.
Sin embargo, algunos casos donde no deberías usar uno de estos motores de búsqueda:
- Los motores de búsqueda están diseñados para devolver pequeñas cantidades de documentos por cada consulta, generalmente entre 10 y 100. Se pueden recuperar más utilizando el sistema de paginación incluido. Consideremos por un momento traernos 1 millón de documentos; la consulta se ejecutará muy rápido, el problema viene al construir la información desde el índice, ya que este índice se almacena en disco de manera que se puedan construir y devolver pequeñas cantidades de documentos, pero tardará mucho tiempo si se tienen que generar muchos documentos a la vez.
- Como ya se ha indicado, estos buscadores no siguen el modelo relacional, por tanto, toda información que tenga unos enlaces padre-hijo muy profundos, debería de ser adaptada al modelo NoSQL y de documentos, ya que, aunque se aceptan querys similares al modelo relacional, estas no son las más adecuadas para el sistema y repercutiría en el rendimiento.
- No están diseñados para garantizar la seguridad de los documentos, al menos no out of the box, por lo que si este aspecto es de vital importancia se debería proteger fuera del ámbito del motor de búsqueda.
No necesito un buscador, pero si una base de datos rápida
Puede que no necesites un buscador como tal o que tus usuarios no necesiten acceder a la información, pero puede interesarte almacenar dicho contenido y ser capaz de consultar rápidamente sobre él.
Ambos productos pueden servir como bases de datos NoSQL perfectamente, aunque ese no sea su cometido real u original.
El único punto aquí es el que ya se ha repetido anteriormente: olvidarse del modelo relacional.
Comparativa Solr vs Elasticsearch. ¿Quién es mejor?
Desde Hiberus como expertos en soluciones big data nos preocupamos por determinar cual es la mejor solución para nuestros clientes en temas de buscadores e indexadores, porque, aunque Solr y Elasticsearch son muy similares, depende de las necesidades de nuestros clientes el elegir uno u otro.

Recogemos sus diferencias en base a una serie de categorías:
Edad
Elasticsearch es mucho más reciente que Solr que aparece en 2004 convirtiéndose en 2006 en proyecto open source bajo el ala de la fundación Apache.
Elastiscsearch fue lanzado en 2010 con el nombre de Compass y a diferencia de Lucene y Solr, no es un proyecto de la fundación Apache y tiene su base en Github.
Eso sí, ambos se utilizan bajo la misma licencia Apache 2.0.
Fue en 2014 cuando Elasticsearch supera a Solr en tendencia y popularidad
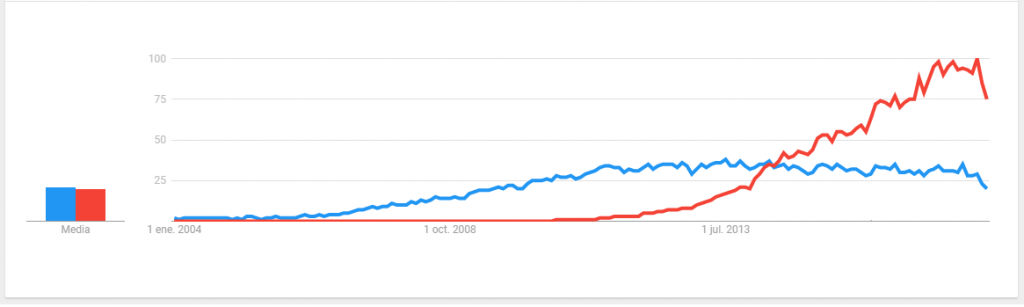
Popularidad
Tomando como referencia DB-Engines podemos ver que la popularidad de ElasticSearch es mucho mayor, doblando a Solr.
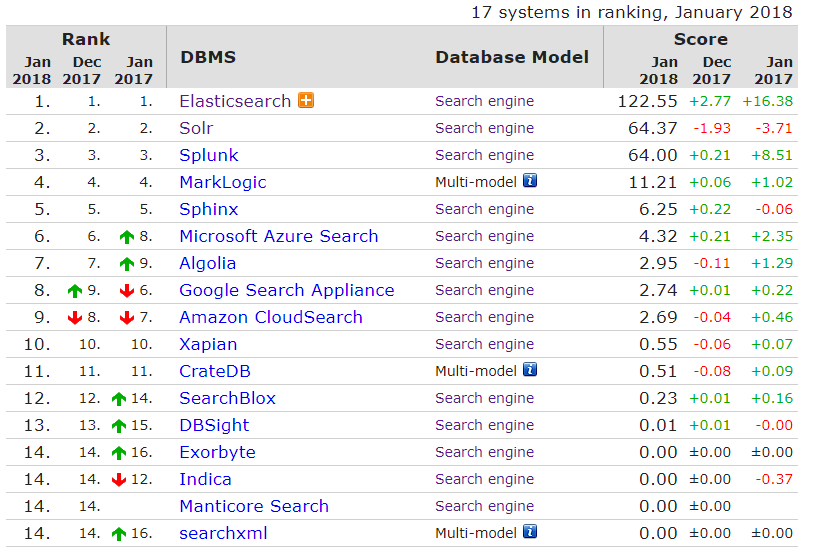
Comunidad y código abierto
Ambos tienen comunidades muy activas con gran cantidad de aportes y trabajando ambas bajo la licencia Apache 2.0 pero difieren en un punto: Solr es realmente código abierto, cualquiera puede ayudar y contribuir. Sin embargo, en Elasticsearch solo los empleados de Elastic Stack pueden aceptar dichas contribuciones.
Ni es bueno ni es malo, es diferente. Solr tendrá muchas más características de calidad aceptable, mientras que Elasticsearch se ceñirá a menos características de la comunidad, pero a un nivel de calidad mucho mayor.
Documentación
Ambos tienen una documentación exquisita y muy detallada. Solr la distribuye a través de Atlassian Confluence y Elasticsearch a través de Github
Núcleo tecnológico
Ambos utilizan Lucene, creación de Doug Cutting, uno de los creadores de Haddop. Por tanto, ambos se asientan sobre una base sólida y difícilmente mejorable de recuperación de información.
Java APIs y REST
Elasticsearch al ser más reciente ha basado su modelo en la API REST Web 2.0 y la REST de Solr es menos flexible. Sin embargo, Solr tiene una mejor API Java con SolrJ (SolrNET para sistemas Microsoft) y en este aspecto Elasticsearch cuenta con Nest y elastisearch.NET respectivamente. Solr soporta JSON aunque inicialmente fue construido para XML, por lo que es más reciente esta adaptación mientras que en Elasticsearch tiene JSON de base.
Las capacidades de exportación también son importantes y en este caso Solr gana al tener capacidad para exportar en diversos tipos de formato out of the box frente a las capacidades limitadas de elastic a solo JSON, ampliable a XML/HTML vía plugins.
Procesamiento de contenido
Solr puede extraer información de archivos binarios utilizando Apache Tika gracias al ExtractRequestHandler. Elastic puede realizar la misma funcionalidad con Logstash que puede leer de cualquier fuente e indexarla.
Escalabilidad
En este punto es donde Solr pierde posiciones y es parte del gran motivo que lleva a la creación de Elasticsearch. El problema inicial en la escalabilidad de Solr fue no renovar el sistema master-slave ya que es un sistema obsoleto. Sin embargo, Elasticsearch ha sabido aprovechar este nicho. Sin embargo, la creación de SolrCloud y la integración con Zookeeper ha hecho posible que Solr escale de manera mucho más rápida y sencilla.
Visión, contexto y ecosistema
Solr está más orientado hacia la búsqueda de texto como motor de búsqueda. Elasticsearch se ha salido de su nicho tras la creación de Elastic Stack (ELK Stack – Elasticsearch, Logstash, Kibana y Beats) que le ha permitido crecer y destacar también en el ámbito de analítica de datos.
Rendimiento
Desde la experiencia de Hiberus se puede apreciar que no hay diferencias en rendimiento entre uno u otro sistema. Se aplica tanto para aplicaciones de búsqueda internas como externas si es que se diseñan, realizan y utilizan correctamente.
Visualización, UI y administración web
Al haberse enfocado en búsqueda de texto, Solr ha perdido un poco la batalla en cuanto a capacidades de generación de informes analíticos que le da Kibana a Elasticsearch. Sin embargo, Solr cuenta con bastantes más plugins y accesorios para conseguir recortar distancias con respecto a Elasticsearch
Conclusiones
Tras haber revisado detenidamente los pros y contras de ambos buscadores, solo podemos decir que ambos son sistemas excepcionales gracias a Lucene, y varían mínimamente. En Hiberus tomamos la decisión adecuada en base al cliente. Tenemos en cuenta los requisitos, tiempos, presupuesto y complejidad del proyecto para aportar la mejor solución como motor de búsqueda o BBDD NoSQL.
Si necesitas ayuda en tu proyecto, escríbenos y nuestro equipo de expertos de Hiberus Digital como consultoría digital estará encantado de ayudarte.
¿Quieres más información sobre nuestros servicios de agencia digital y tecnología para ecommerce?
Contacta con nuestro equipo de hiberus digital

Artículo muy completo y detallado, a la vez que simple.
Me ha ayudado bastante para un proyectillo que tengo entre manos.
Quizás algún día podamos trabajar juntos.