

El reconocimiento de duplicados consiste en la identificación de registros referentes a una misma entidad sin la ayuda de identificadores unívocos.
Este problema se puede clasificar dependiendo de la naturaleza de los datos en:
- Deduplicación: si los datos provienen de una misma base de datos.
- Vinculación de registros: si los datos provienen de distintas bases de datos, cada una de las cuales no tienen registros duplicados por sí mismas.
- Resolución de entidades: si se tienen datos de distintas fuentes y, además, hay duplicados dentro de cada una de ellas.
Esta clasificación del problema puede permitir definir condiciones lógicas sobre los registros a comparar, de tal manera que se reduzca el espacio de búsqueda del problema. Por ejemplo, en el caso de la deduplicación de datos se puede usar la condición de transitividad. Es decir si dos registros son catalogados como duplicados y un tercer registro resulta ser duplicado del segundo, entonces también ha de ser duplicado del primero.
En el caso de la vinculación de registros resulta importante la exclusividad. Es decir si dos registros de dos bases de datos son duplicados, entonces no puede haber más duplicados si cada base de datos respeta la unicidad de sus registros.
En general se pueden aprovechar diversas condiciones sobre los datos más allá de la clasificación del problema. Estas condiciones muchas veces van a depender de la naturaleza de los datos. Por ejemplo:
- Si se tienen dos bases de datos en un problema de vinculación, cada una de las cuales tiene una tabla de papers y una tabla de autores y se encuentra que un paper es duplicado de otro, entonces necesariamente los autores de esos papers han de ser duplicados también.
- En un problema de deduplicación puede haber un número máximo de duplicados.
- Puede haber columnas que sirvan como identificadores parciales.
Luego de haber generado las condiciones para delimitar el espacio de búsqueda, generalmente estos algoritmos se valen de reglas de similitud entre los registros para poder clasificar todos los pares de manera probabilística, en inciertos, duplicados y distintos.
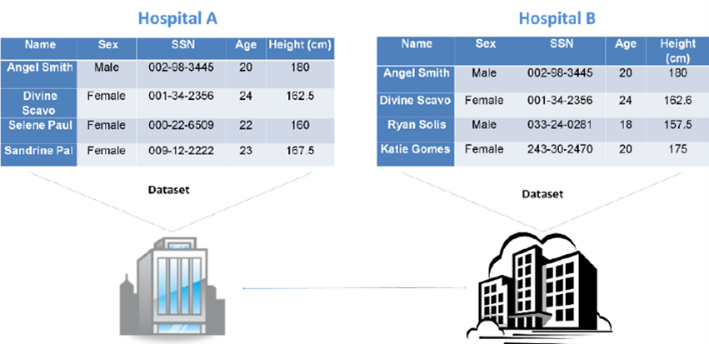
Ejemplo de vinculación de pacientes.
Desafíos específicos a la minería de datos en el reconocimiento de duplicados
Para poder aplicar exitosamente estos procedimientos típicamente estos algoritmos tienen que enfrentarse a problemas comunes en la IA y la minería de datos:
- Ambigüedad en cuanto a los atributos.
- Errores durante la entrada de datos.
- Valores faltantes.
- Atributos cambiantes.
- Formato de datos.
- Abreviaturas.
- Truncamiento.
Para poder enfrentar estos problemas resulta de suma importancia diseñar e implementar una política de preprocesamiento de datos que no induzca falsos positivos.
Desafíos específicos a la ingeniería de datos en la deduplicación
Adicionalmente, si bien el conjunto original de datos puede no ser grande, el conjunto de pares de registros implica un espacio del orden de O(N2) que sí puede ser desafiante. Esto ocurre porque la deduplicación de datos es como mínimo un cruce de una tabla consigo misma. Por ello, se tienen los siguientes desafíos:
- Complejidad en tiempo y espacio de O(N2) para un conjunto de datos de tamaño N.
- Conjuntos de pares grande.
- Datos no estructurados e incompletos. Por ejemplo, si hay texto.
- Necesidad de extraer relaciones diferentes a la igualdad. Esto suele ocurrir si las condiciones lógicas de filtro vienen dadas por desigualdades o por condicionales.
- Múltiples relaciones. Por ejemplo, si las bases de datos a deduplicar tienen más de una tabla.
- Múltiples dominios. Esto puede ocurrir si las bases de datos proceden de modelos de negocio totalmente distintos. Por ejemplo, una base de datos de pacientes y una base de datos de registros civiles.
- Múltiples aplicaciones con distintas necesidades. Esto resulta relevante si se tiene en cuenta que los resultados de los algoritmos de deduplicación suelen arrojar una certeza en sus resultados.
En este caso para poder enfrentar estos problemas resulta fundamental la elección de las herramientas de trabajo. Adicionalmente, el diseño de las condiciones lógicas de filtro es probablemente el aspecto más importante del proceso, pues esto contribuye a reducir el número de pares de registros que se comparan. A este proceso se le conoce como blocking.
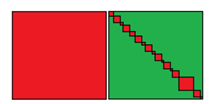
Cantidad de pares a considerar antes de las reglas de filtro y después de aplicarlas
Herramientas, algoritmos y técnicas para la duplicación de datos
Blocking
Son técnicas aplicadas directamente sobre el conjunto de registros para poder delimitar los pares de estos que pueden ser comparados. Generalmente estas técnicas se valen de identificadores parciales, sin embargo es posible aplicar diversos tipos de algoritmos de IA o incluso métricas como TF-IDF.
Paquetes
La mayoría de los paquetes usados para la deduplicación de datos resulta experimental. Adicionalmente, de los paquetes que son suficientemente maduros como para poder ser usados en producción, no todos son escalables o implementan algoritmos de aprendizaje poderosos.
A continuación se mencionarán algunos ejemplos.
Splink
Este es un paquete implementado para Apache Spark que implementa una versión del modelo Fellegi-Sunter y usa el algoritmo Expectation Maximization para aprender de manera no supervisada sus parámetros.
La principal ventaja de este paquete es su escalabilidad y lo simple que resulta su uso debido a que es no supervisado. Adicionalmente, fue implementado para el Gobierno británico, lo cual permite asegurar que el proyecto seguirá siendo mantenido. Por otro lado su principal desventaja es que este modelo asume la independencia estadística de sus atributos.
Dedupe
Es un paquete implementado para Python que se vale de datos etiquetados y aprendizaje activo para poder entrenar sus modelos. A diferencia de Splink, este paquete no cuenta con una plataforma de Big Data para distribuir sus tareas. Sin embargo, es posible usar esta herramienta con cursores conectados a bases de datos para evitar sobrecargar la memoria durante sus cálculos .
Su principal ventaja radica en sus algoritmos de aprendizaje para los bloques y las reglas de comparación. Presenta una desventaja que radica en la complejidad con la que se pueden sortear sus problemas de escalabilidad.
Duke
Es una plataforma implementada en Java que se vale de conectores a bases de datos y motores de indexación para deduplicar registros. Entre sus ventajas está su eficiencia debida al uso de Lucene y su principal desventaja es, al igual que Splink, su dependencia a las hipótesis estadísticas .
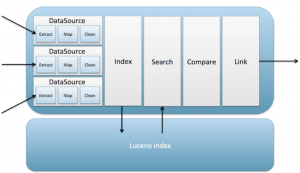
Arquitectura de Duke
JedAI
Es una plataforma gráfica implementada en Java y que puede ser usada con Spark y Docker. Entre sus principales ventajas está la disponibilidad de varios algoritmos basados en el Estado del Arte, su interfaz de usuario y su capacidad de trabajar con datos no estructurados.
Su principal desventaja es que requiere de un “Golden Standard”, además de los datos a deduplicar.
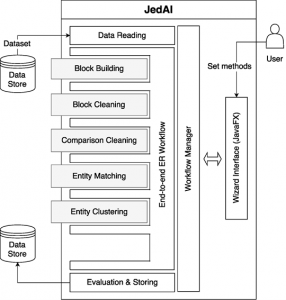
Arquitectura de JedAI
Ejemplo: deduplicación de inmuebles entre portales inmobiliarios
Se cuenta con cantidades ingentes de datos provenientes de varios portales de anuncios inmobiliarios en GCP. Un mismo inmueble puede ser ofertado varias veces en:
- Distintos portales.
- En el mismo portal, usualmente de manera adversativa en contra de las normativas de éste.
Problema:
Identificar cuáles registros corresponden a la misma propiedad para poder, así, contar con datos fiables que puedan ser usados en procesos analíticos partiendo de BigQuery y GCS.
Solución:
Se puede implementar un Workflow Template en Dataproc con una tarea de PySpark. Esta tarea contaría con un paquete de vinculación de registros no supervisado llamado Splink. Entre las razones por las que se podría usar Splink, tenemos:
- El volumen de los datos presupone que se requiere una herramienta de Big Data como Apache Spark.
- Preferencia por Python.
- Practicidad y rapidez en cuanto al uso de un método no supervisado.
Desafíos:
Al igual que cualquier proyecto similar, uno de los mayores desafíos podría consistir en la baja granularidad de los datos en cuanto a pisos construidos en una misma planta o en un mismo edificio. En estos casos un mismo usuario de los portales inmobiliarios podría repetir la información de estos.
Adicionalmente si no se cuentan con campos para distinguir sus puertas, entonces resultaría imposible no detectarlos como distintos.
En Hiberus contamos con un área de especializada en el análisis y tratamiento de datos, Data & Analytics. Somos expertos en inteligencia artificial, machine learning y deep learning.
¿Quieres más información sobre nuestros servicios de Data & Analytics?
Contacta con nuestro equipo de expertos en Data & Analytics
