

Google Cloud Computing ofrece muchos servicios diferentes para cubrir las necesidades de procesamiento de datos y aplicaciones Big Data. En este artículo hablamos acerca de los servicios para crear un “data pipeline” o tubería de datos, es decir, la carga, preparación y limpieza de datos sobre esa plataforma.
A continuación, se explica la utilidad de cada uno de estos servicios, sus beneficios y una aproximación al cálculo de su coste.
Todos los servicios de Google Cloud Computing para Big Data
Primero se hablará sobre los servicios que ofrece Google Cloud Computing para el almacenamiento de datos, lo siguiente serán las herramientas de ingesta de datos y se finalizará con la preparación y procesamiento de los datos.
1. Servicios de almacenamiento de Google Cloud Computing
Cloud Storage
Cloud Storage ofrece un servicio de almacenamiento de objetos de alta durabilidad que se puede escalar hasta exabytes de datos. Proporciona un acceso instantáneo a los datos desde cualquier servicio.

Sus características principales son:
- Almacenamiento persistente.
- Área de pruebas para otros servicios.
- Forma de almacenamiento en clases.
- Control de acceso por cada proyecto, se organiza en “buckets”.
- Almacenamiento utilizado tanto en streaming como en batch.
- Soporte de versionado.
- Soporte de múltiples opciones de encriptación.
La característica más destacada de Cloud Storage es la capacidad de almacenar cualquier tipo de archivo: desde CSV, JSON, AVRO, hasta imágenes.
El precio se basa en la cantidad de datos almacenados, los recursos de red, la cantidad de operaciones realizadas sobre esos datos. Es decir, cuanto mayor sea el peso del archivo y cuantos más accesos se hagan al mismo, mayor será el precio. Este tipo de almacenamiento suele llamarse “Cold”, ya que no se realizan muchas operaciones. El precio estándar es por 1GB de datos almacenados.
Si se va a realizar un almacenamiento de datos histórico, o de datos sin estructurar y sin SDK móvil, las mejores prácticas de Google recomiendan usar Cloud Storage.
Cloud BigTable
BigTable se trata de una base de datos tipo NOSQL, Google recomienda usar este tipo de base de datos para tecnologías de anuncios, finanzas o IOT. Esta base de datos está destinada a un alto rendimiento.

Sus características principales son:
- Latencia constante por debajo de los 10 ms.
- Alto rendimiento.
- Acceso diseñado para optimizar el rango de celdas mediante prefijos de llave.
- Esquema definido.
- Control de acceso.
- Diseño de rendimiento.
- Escoger entre HDD y SSD
- Bueno para un almacenamiento columnar.
- Sin servidor (Serverless)
Cloud Bigtable es un servicio de base de datos NoSQL rápido, totalmente gestionado y con enorme escalabilidad. El precio varía dependiendo del almacenamiento que se use, si es SSD será bastante más caro que usar HDD, pero la velocidad también varía proporcionalmente al precio.
Si los datos no son estructurados y necesitan un análisis además de muchas transacciones con baja latencia, las mejores prácticas de Google recomiendan usar Cloud BigTable.
BigQuery
BigQuery es el producto estrella de Google Cloud, es un almacén de datos en la nube de bajo coste, gran escalabilidad y sin servidor (completamente administrado por Google) diseñado para tomar decisiones. Permite almacenar y consultar conjuntos de datos masivos.

Sus características son:
- Almacenamiento de petabytes
- Familiarizado con bases de datos relacionales
- Se estructura en forma de tablas que se almacenan de forma columnar
- Permite la consulta de toda la información a través de ANSI SQL
- Integrado con todos los servicios de GCP
- Permite la explotación de información almacenada en otros medios como Cloud Storage o bases de datos externas como MySQL, Oracle, …
- Máximo número de celdas es 10MB
Se paga por separado la información almacenada y el número de consultas por GB. Se puede pagar por terabyte o por coste mensual dependiendo de las preferencias.
Si se desea hacer un “Cold”, BigQuery no es el adecuado ya que se cobra por consulta y no por información almacenada. Por lo tanto, se utiliza si se van a realizar consultas y transacciones con los datos que estén recientes.
Comparativa de los servicios de almacenamiento de Google Cloud Computing
| Cloud Storage | Big Table | Big Query |
|
– Almacenamiento persistente. – Almacenamiento en clases. – Estructura en carpetas llamados buckets – Almacenamiento tanto en streaming como en batch. – Almacenamiento de datos sin estructurar
|
– Base de datos NOSQL columnar
– Basado en Hbase – HDD o SDD – Ingesta frecuente – Grandes volúmenes de datos (IoT) – Latencia en milisegundos |
– Nivel de Petabytes
– Base de datos SQL – Consulta OLAP – Uso para visualización y almacenado – Almacenamiento de tablas en columnas – Latencia en segundos |
Los servicios que hemos explicado son para usos analíticos de la información. En la representación siguiente se pueden ver todos los productos que ofrece Google Cloud para el almacenamiento.
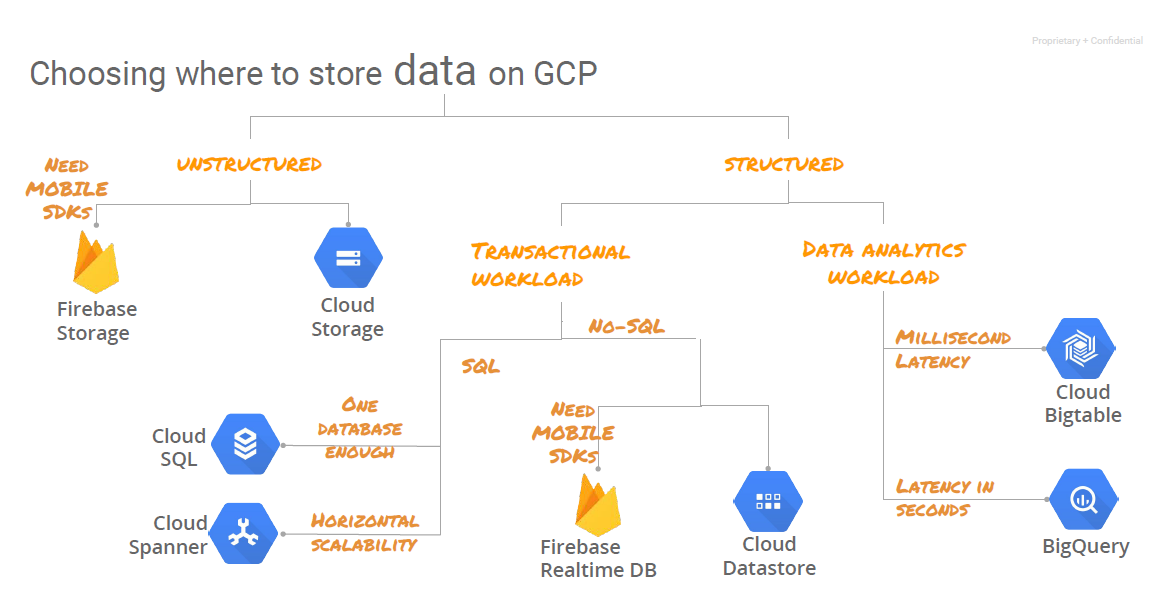
2. Servicio de ingesta de Google Cloud Computing
Cloud Pub/Sub
Con Google Pub/Sub se pueden enviar mensajes entre aplicaciones, está diseñado para proporcionar mensajes asíncronos, fiables y con varios remitentes y destinatarios. El remitente envía la información a un topic mientras que el destinatario se suscribe al mismo para consumirlo.
Mediante este servicio los mensajes se transferirán de forma segura, rápida y asíncrona. Hace uso del patrón publish / subscribe messaging.
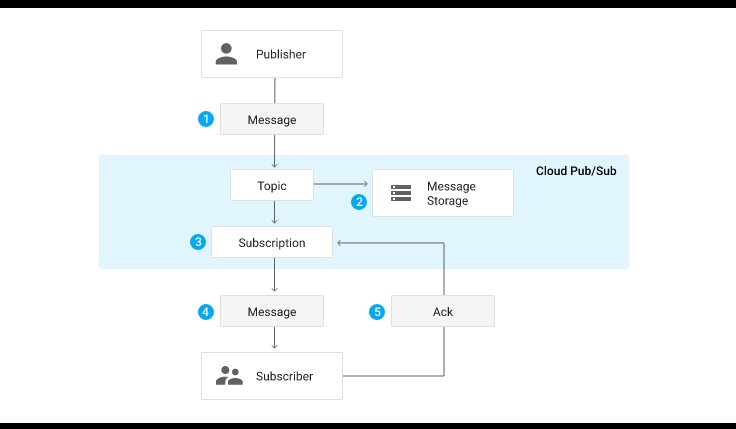
Como se puede apreciar en la figura anterior el publicador no se conecta con el subscriptor de forma directa, sino que lo hace a través de un topic, que es una cola de mensajería, de esta manera garantizamos que no haya perdida de datos. Después el subscriptor se subscribe y recoge ese topic. Es el mismo mecanismo que utiliza el proyecto open Source Apache Kafka.
Sus características son:
- Capa de comunicación muy confiable
- Alta capacidad
- El tamaño máximo para un mensaje es de 10 MB
- El tamaño máximo para una solicitud es de 10 MB
Cuanto más se use más barato es. No hay costes por adelantado ni se cobra un importe por crear o mantener topics y suscriptores.
3. Servicios de preparación y procesamiento
Cloud Functions
Se trata de una plataforma de computación sin servidor basada en eventos de Google Cloud. Se trata de un servicio en el cual puedes ejecutar el código en la nube sin necesidad de un servidor.

Sus características son:
- Serveless, sin necesidad de un servidor
- Escalado automático
- Simplifica el desarrollo de aplicaciones
- Funciones de supervisión, almacenaje y análisis.
- Utiliza Faas, funciones como servicios
En Cloud Functions se paga por el tiempo de ejecución del código de tus funciones, las veces que se invoca y los recursos que consume. Las primeras 2 millones de invocaciones al mes son gratuitas.
Cloud functions sirve de gran ayuda si se requiere realizar operaciones con unos datos de un tamaño de hasta 2 GB, por lo tanto, si se va a operar datos menores de 2GB es una muy buena alternativa.
Cloud Run
Se trata de una plataforma de computación gestionada que escala tus contenedores sin reconocer los estados. Este servicio podría decirse que es igual que la herramienta open source Docker, la cual gestiona contenedores, solo que Cloud Run.

Sus características son:
- Despliega contenedores http sin estado en cualquier lenguaje
- Abstracción de gestionar una infraestructura
- No requiere una administración de servidores
- Ejecuta un contenedor en producción en segundos
Solo se paga por recursos utilizados, una vez que esté ejecutando el servicio solo se empieza a cobrar cuando se ejecute la función y no cuando se activa el contenedor.
Por lo tanto, podemos decir que se trata de un servicio bastante barato para la cantidad de servicios que ofrece y para tareas que no manejan muchos datos se podría utilizar en vez de Cloud Functions cuando se requiera alguna característica especial o particular.
Cloud DataFlow
DataFlow es un servicio de procesamiento de datos de una forma rápida y unificada en tiempo real y por lotes. Desarrolla y ejecuta un gran número de patrones de procesamiento de datos, el más destacado es para procesos ETL.

Se muestra la ejecución de un “pipeline” de datos de ejemplo:
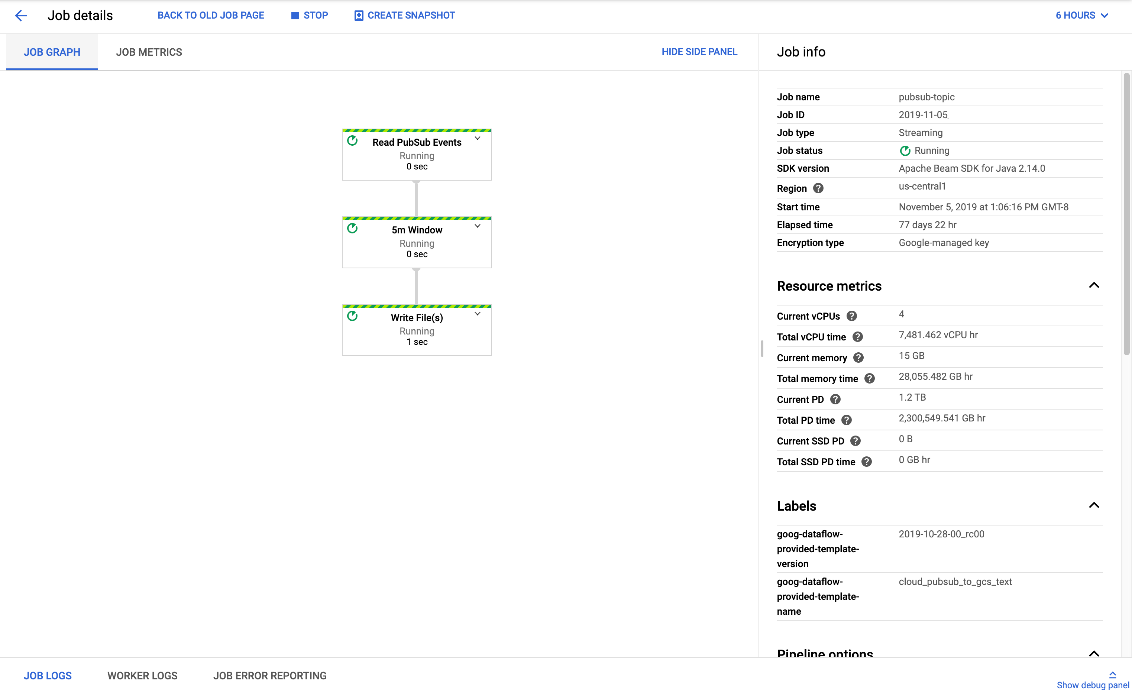
Este servicio está basado en el proyecto open source Apache Beam.
Sus características son:
- Permite la programación en tiempo real y en batch utilizando la misma API
- Rápido despliegue
- Servicio gestionado al 100%
- Balanceo de carga
- Basado en un estándar open-source como Apache Beam
- El tamaño máximo de los datos en tiempo real es de 100Mb
- Procesamiento exacto, fiable y uniforme
El precio de DataFlow se factura por segundos, por el uso real del procesamiento en paralelo o por lotes. Las tareas de otros recursos cloud van incluidas dentro del precio de este servicio.
Es el servicio principal para procesamiento de grandes cantidades de datos en Google Cloud junto a DataProc. Está más preparado que DataProc para el tiempo real. Por el contrario, aunque está basado en un estándar open-source, es más complejo de traspasar a otro entorno Cloud y hay menos desarrolladores que conozcan el estándar Apache Beam frente a Apache Spark.
Cloud DataProc
Se trata de un servicio que permite gestionar los clústers de spark y hadoop en Google Cloud. Con Dataproc se puede crear un clúster de instancias, cambiar dinámicamente el tamaño del clúster, configurarlo y ejecutar allí trabajos de Spark y/o MapReduce.
Sus características son:
- Clúster con los servicios HDFS, Hadoop, Hive, Pig y Spark
- Procesamiento rápido y escalable
- Auto – escalado
- Almacenamiento no persistente. La idea es que una vez se finalice el procesamiento de los datos, se muevan a otro tipo de almacenamiento como Cloud Storage o Big Query.
Aunque el clúster no esté en funcionamiento se factura, por lo que se recomienda que una vez completada su función se elimine el clúster. Si no se elimina el clúster este seguirá consumiendo y por lo tanto GCP seguirá facturando. Es muy económico si se trata de ejecutar procesos que manejan grandes cantidades de datos durante un tiempo limitado.
Dataproc es una herramienta muy útil si se desea procesar una gran cantidad de datos utilizando Cloudera (hadoop,spark,hive..). Se debe crear un clúster, realizar la función y eliminar el clúster. Como se comentaba antes, quizás sea mejor opción para procesos batch que procesos en tiempo real donde sería más económico y fácil utilizar DataFlow.
Clod DataPrep
Cloud DataPrep es una herramienta de visualización y preparación de datos sobre una interfaz web, lo que se conoce como herramienta de “data wrangling” Sirve para examinar, limpiar y preparar los datos (tanto estructurados como no estructurados).

Se utiliza para construir tuberías ETL de un origen, normalmente Google Cloud Storage, y se envían a un destino, generalmente BigQuery para su posterior análisis.
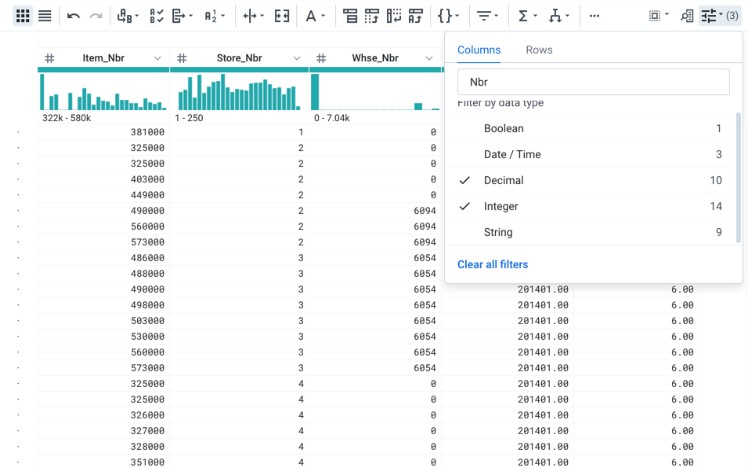
Sus características son:
- Simplifica la construcción de ETL
- Interfaz web clara
- Automatiza trabajos manuales
- Incorpora la programación por lo que no hay código en la interfaz
- Funciona solo con los orígenes y destinos BigQuery y Google Cloud Storage.
- Sin servidor
- Transformación predictiva
- Genera flujos DataFlow
El uso de esta herramienta para mostrar datos es gratuita, hay que pagar por el almacenamiento y si se utiliza el flujo se genera un trabajo de DataFlow que es por lo que se facturaría.
Esta herramienta es la integración del producto Trifacta dentro de la plataforma Google Cloud y es muy útil para analizar fuentes de datos donde la calidad no es buena o para preparar fuentes de una manera muy ágil para procesos posteriores de Machine Learning.
Cloud Data Fusion
Se trata de un servicio que proporciona Google Cloud para la integración de datos en la nube de forma totalmente gestionada.

Gracias a Data Fusion, cualquier persona puede crear un procesamiento de datos ETL, gestiona tanto la extracción como la transformación y la carga de datos mediante el uso de una interfaz gráfica totalmente gestionada.
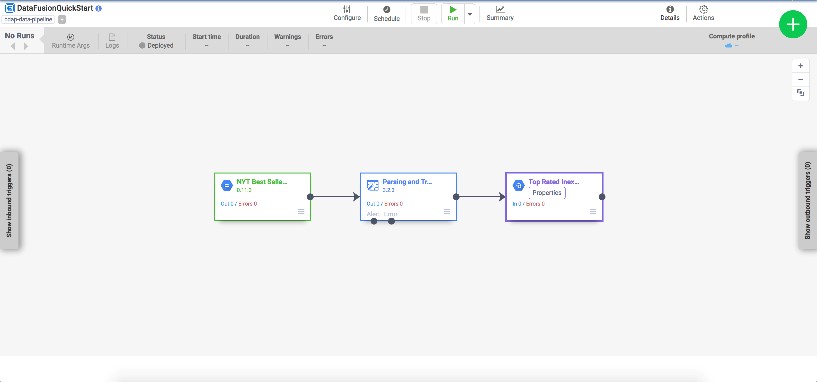
Sus características son:
- Despliegue sin código
- Ingeniería de datos colaborativa
- Arquitectura nativa GCP
- Basado en el estándar CDAP
- Genera código para ejecutar en DataProc
Se trata del servicio más caro de Google Cloud en el cual se paga por hora de la instancia de Data Fusion, por el número de flujos y por el número de clústers activos de dataproc.
Este servicio tiene sentido para organizaciones grandes donde se quieran desarrollar “pipelines” de datos de una forma no codificada, es decir, no sea necesario el disponer de muchas personas con conocimientos técnicos de lenguajes como Python, Spark, … La comodidad que ofrece DataFusion es tener toda la arquitectura ETL integrada en una herramienta visual.
Resumen de servicios de procesamiento de Google Cloud Computing para Big Data
| Cloud Functions | Cloud Run | DataFlow | DataProc | DataPrep | Data Fusion |
| – Serveless
– Escalado automático – Simplifica el desarrollo de aplicaciones – Funciones de supervisión, almacenaje y análisis. – Utiliza Faas, funciones como servicios
|
– Despliega contenedores http sin estado en cualquier lenguaje
– Abstracción de gestionar una infraestructura – No requiere una administración de servidores – Ejecuta un contenedor en producción en segundos
|
– Programación en tiempo real y por lotes con una API
– Rápido despliegue – Servicio gestionado – Basado en Apache Beam – El tamaño máximo de los datos en tiempo real es de 100Mb – Procesamiento exacto, fiable y uniforme
|
– Creación de clústers de Spark y hadoop
– Soporta varios lenguajes de programación – Procesamiento rápido y escalable – Auto- escalado. – Barato para crear y ejecutar
|
– Simplifica la construcción de ETL
– Interfaz web – Automatización de trabajos – Genera código de DataFlow – Sin servidor – Transformación predictiva
|
– Desarrollo visual sin necesidad de código
– Ingeniería de datos colaborativa – Arquitectura nativa GCP – Genera código de DataProc
|
Hiberus cuenta con una unidad especializada en servicios de Data & Analytics formada por un equipo de profesionales comprometidos, responsables, cercanos, especializados y competitivos con amplio expertise en tecnología, análisis de datos e innovación. Desde esta unidad se ofrecen soluciones integrales de consultoría estadística y análisis de datos con especialización por áreas de conocimiento, donde se acompaña a nuestros clientes en cada proyecto integrándonos como parte de su equipo. Ponte en contacto con nosotros y estaremos encantados de ayudarte.
¿Quieres más información sobre nuestros servicios de Google Cloud?
Contacta con nuestro equipo de expertos en Google Cloud
