

El ritmo imparable en la evolución de las nuevas tecnologías que se lleva produciendo desde hace ya unos cuantos años lleva asociado un nivel de exigencia cada vez mayor por parte de los usuarios. Centrándonos en el mundo web, cada vez son menos los negocios u organizaciones que no disponen ya de su portal de contenidos o su e-commerce. Por lo tanto, si queremos que nuestra web de contenidos o comercio electrónico sea aceptado por los usuarios debemos considerar una serie de factores, que de no ser tenidos en cuenta harán que los usuarios, insatisfechos con el uso de nuestra web, se vayan a las de la competencia. Si no los tenemos en cuenta, los usuarios, insatisfechos con el uso de nuestra web, se irán a la competencia y es aquí donde entra la importancia de la creación de un motor de indexación y búsqueda con Elasticsearch.
Por qué es importante la indexación
Uno de los factores más importantes es la facilidad con la que cada usuario encuentra lo que está buscando en nuestro portal. Para ello, además de una adecuada estructuración y clasificación de nuestros contenidos o productos, es fundamental disponer del mejor motor de búsqueda “inteligente”, que sea capaz de anticiparse a lo que el usuario está buscando (sugerencias), que sea tolerante a errores de escritura, que sea rápido… En definitiva, que permita al usuario encontrar lo que busca de forma rápida y sencilla.
En un e-commerce, las búsquedas se realizan sobre el catálogo de productos, mientras que en una web de contenidos esta búsqueda se realiza sobre noticias, eventos, información corporativa, etc. En ambos casos, por lo que al motor de búsqueda se refiere, se están incluyendo (indexando) en los índices de búsqueda documentos compuestos por un conjunto de campos (nombre, título, descripción, etc.).
El grado de fiabilidad de las búsquedas realizadas por los usuarios, y su grado de satisfacción con los resultados obtenidos van a ser determinantes en el éxito de nuestro e-commerce o de nuestra web. Por lo tanto, es fundamental elegir el motor de búsqueda e indexación de forma adecuada. Dependiendo del motor de búsqueda elegido, hay una serie de aspectos a tener en cuenta y decisiones a tomar.
En el artículo Apache Solr vs ElasticSearch se habló de los dos motores de búsqueda open source más utilizados, y de las diferencias entre ellos.
En este artículo nos centraremos en Elasticsearch y en los factores determinantes en el diseño y contrucción de nuestro buscador basado en el motor de Elastic.
Mapping o estructura de los datos en el índice
Una de las primeras decisiones a tomar es cómo vamos a almacenar y estructurar la información en el índice, es decir, qué campos contendrán los documentos a almacenar en el índice, de qué tipo (texto, numérico, booleano, etc.) y si los campos se analizarán al indexarse o no. Esta definición es lo que se denomina mapping en Elasticsearch.
En primer lugar, debemos decidir si el mapping será dinámico, es decir, no existirá una estructura fija para los documentos en el índice (se irán añadiendo nuevos campos al mapping automáticamente según lleguen documentos que incluyan nuevos campos), o si por el contrario será estricto, es decir, la estructura de los documentos será fija y cualquier documento deberá ceñirse a esta estructura para poder ser insertado en el índice. Cada una de las dos opciones es más adecuada para un tipo de situaciones y la decisión no debe tomarse a la ligera, si bien a nivel general podemos decir que el mapping estricto suele ser más adecuado salvo en los casos en los que la estructura de la información a indexar no es conocida a priori.
Análisis de los campos en tiempo de indexación
Otro punto fundamental en un motor de búsqueda, relacionado con el anterior, es tener claro qué campos se usarán en búsquedas full-text y cuáles se usarán en facetas (para agrupar los resultados y permitir navegación guiada). Esto determinará la forma en la que debe indexarse cada campo.
Los campos que vayan a utilizarse para búsquedas de texto deben ser analizados en indexación, de forma que se transformen y se almacenen en el índice de la forma más adecuada. Las transformaciones (separar palabras, eliminar sufijos y plurales, pasara a minúsculas, etc.) realizadas dependerán del analizador que utilicemos, y son las que permiten que un texto pueda ser encontrado independientemente de si lo buscamos en mayúsculas o minúsculas, en singular o plural, etc.
Elasticsearch viene con un gran número de analizadores disponibles, cada uno de los cuales realiza ciertas transformaciones. Cada analizador está compuesto por una cadena de filtros, que se ejecutan en secuencia sobre los textos a indexar, de forma que las transformaciones que realiza cada analizador dependen de los filtros que utiliza. Además, podemos crear nuevos analizadores combinando los filtros ya existentes en Elasticsearch o creando nuevos filtros.
Ejemplos de campos de un documento (producto o contenido) que suelen indexarse de esta manera suelen ser el nombre, el título o la descripción.
A continuación, se presenta un ejemplo de la definición de un analizador:
"analysis": {
"filter": {
"spanish_stop": {
"type": "stop",
"stopwords": "_spanish_"
},
"spanish_keywords": {
"type": "keyword_marker",
"keywords": ["ejemplo"]
},
"spanish_stemmer": {
"type": "stemmer",
"language": "light_spanish"
}
},
"analyzer": {
"spanish": {
"tokenizer": "standard",
"filter": [
"lowercase",
"spanish_stop",
"spanish_keywords",
"spanish_stemmer"
]
}
}
}
Los campos que vayamos a utilizar como facetas para agrupar los resultados (por ejemplo, agrupar los resultados por color, por rangos de edad, por género… y permitir ir refinando la búsqueda en base a estos grupos) deberán indexarse sin ser analizados, es decir, sin ninguna transformación. Campos típicos que suelen indexarse de esta forma son campos con un número limitado de valores posibles (color, género, origen, …) o campos numéricos o de tipo fecha, para poder agrupar por rangos de precios, de edad, de fechas, etc.
En Elasticsearch los campos que queremos indexar de esta forma los indexaremos como tipo keyword, o con el tipo numérico adecuado en el caso de que vayan a utilizarse para agrupar por rangos.
En algunos casos, un mismo campo necesitamos utilizarlo para búsquedas de texto pero también vamos a utilizarlo para agrupar los resultados. Por ejemplo, la marca la utilizaremos para agrupar resultados, pero también queremos utilizarla en las búsquedas de texto, para que si el usuario teclea la marca los productos de esa marca aparezcan entre los primeros resultados de búsqueda. Para estos casos, Elasticsearch nos permite indexar un mismo campo de las 2 maneras, de forma que según vayamos a utilizarlo en búsqueda de texto o como faceta lo referenciaremos de una forma u otra. Por ejemplo, en el caso de la marca el mapping sería
"brand": { "type": "text", "analyzer": "simple", "fields": { "raw": { "type": "keyword" } } }
En búsquedas full-text usaríamos el campo brand, y agruparíamos los resultados por por brand.raw
Número de índices
El número de índices que utilicemos para indexar la información es también importante. Versiones anteriores a la 6.x de Elasticsearch permitían crear diferentes tipos de documento dentro de un mismo índice, pero a partir de esta versión desaparece el concepto de tipos de documento, por lo que todos los documentos almacenados dentro de un mismo índice deben tener un mismo mapping. Por lo tanto, si tenemos varios tipos de documento con una estructura totalmente diferente, deberíamos utilizar índices diferentes para almacenarlos.
Sin embargo, a mayor número de índices mayor consumo de memoria, por lo que hay que buscar un equilibrio entre el número de índices y el tamaño del mapping (número de campos diferentes) de cada índice, ya que un mapping demasiado grande puede derivar en problemas de rendimiento.
Soporte para multiidioma
Si la información a indexar va a estar disponible en varios idiomas, deberemos decidir entre dos alternativas:
- Utilizamos un solo índice para todos los idiomas, en el que cada campo traducible del documento tiene un campo diferente por cada idioma en el índice.
- Creamos un índice por idioma, y en cada uno de ellos tenemos la misma información, pero traducida al idioma correspondiente.
A la hora de optar por una u otra solución debemos tener en cuenta factores como el número de idiomas, el porcentaje de campos traducibles frente a campos no traducibles, si se van a lanzar búsquedas contra varios idiomas a la vez y el número total de campos a indexar.
Es importante destacar que Elasticsearch ofrece analizadores para multitud de idiomas, que analizan los textos teniendo en cuenta las reglas propias de ese idioma, y por tanto es recomendable utilizar para cada campo el analizador correspondiente al idioma de ese campo o índice, para conseguir unos resultados de búsqueda más refinados.
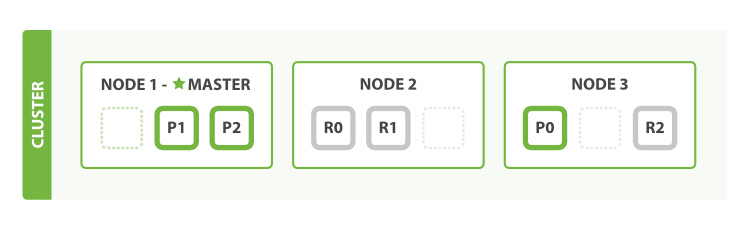
Configuración del cluster
Elasticsearch está especialmente preparado para la configuración en cluster. En base a unas propiedades básicas, cuando los diferentes nodos arrancan el cluster se configura automáticamente, y cuando alguno de los nodos queda inaccesible si el cluster está correctamente dimensionado el resto de nodos asumen las funciones del nodo inaccesible, de manera que el cluster continúa 100% operativo.
Dependiendo del número de documentos a indexar y del tamaño de estos, del número de índices y del volumen y tipo de queries esperadas deberá dimensionarse adecuadamente el cluster, tanto en número de nodos como en la configuración de cada uno de ellos (shards, réplicas, memoria dedicada, cuántos de ellos son elegibles como master, si son nodos de datos, etc.).
Tipos de búsquedas
Finalmente, tenemos que tener claro qué tipos de búsquedas se van a realizar, y los múltiples mecanismos que nos ofrece Elasticsearch para refinarlas hasta obtener el comportamiento deseado. Para tener una mejor idea de las búsquedas que pueden realizar los usuarios, serán muy útiles algunas herramientas de analítica digital.
En primer lugar, es importante entender el concepto de scoring. Elasticsearch cuando realiza una búsqueda otorga (utilizando diferentes criterios) una puntuación a cada uno de los documentos encontrados. Esta puntuación es lo que se denomina scoring, y los resultados de búsqueda son devueltos ordenados de mayor a menor scoring (salvo que indiquemos algún criterio de ordenación diferente al lanzar la búsqueda). El algoritmo utilizado por Elasticsearch para calcular el scoring de los diferentes documentos puede ser personalizado para ajustarlo a nuestras necesidades.
En la mayoría de los casos, las búsquedas de texto deben lanzarse sobre varios campos del documento (nombre, descripción, etc.). Para esto, Elasticsearch ofrece la búsqueda multi_match, que permite especificar un listado de campos sobre los que buscar el texto. Además, existen diferentes tipos de búsqueda multi_match, dependiendo de cómo queramos que Elasticsearch calcule el scoring: se suma el scoring de todos los campos en los que se encuentre el texto, para cada documento solamente cuenta el scoring del campo que hace mejor matching, etc.
También podemos indicar, en una búsqueda multi_match, la relevancia de cada uno de los campos de búsqueda, es decir, qué campo de los indicados es más importante. Por ejemplo, podemos especificar que el campo nombre sea el doble de importante que el campo descripcion, de forma que si un texto aparece en el nombre de un documento y en la descripción de otro, el primer documento tendrá el doble de scoring que el segundo.
Otras funcionalidades que podemos utilizar para refinar las búsquedas son:
- Mimimum_should_match, para especificar el % de las palabras del texto de búsqueda que deben aparecer en un documento para que sea incluido en los resultados de búsqueda
- Tolerancia a errores de escritura (fuzziness), pudiendo indicar el número de letras no coincidentes que permitimos para que un texto sea considerado un match.
- Combinación de varias sub-queries mediante operadores lógicos (must, must_not, should, etc.)
Además, en tiempo de búsqueda podemos indicar a Elasticsearch cómo queremos que nos agrupe los resultados: es lo que se denominan facetas o, en el caso de Elasticsearch, aggregations. El único requisito es que los campos que indiquemos como aggregations sean numéricos o fechas (para aggregations de rango) o hayan sido indexados como keywords.
Finalmente, si deseamos que el buscador ofrezca sugerencias mientras estamos tecleando, o queremos funcionalidad search-as-you-type, como es una de las tendencias del ecommerce actualmente, debemos tenerlo en cuenta a la hora de definir el mapping del índice, pues Elasticsearch ofrece filtros y tipos de datos especialmente preparados para analizar e indexar la información de forma optimizada para este tipo de búsquedas.
Hemos visto los factores más importantes a tener en cuenta a la hora de diseñar nuestro motor de indexación y búsqueda con Elasticsearch. Las posibilidades que nos ofrece este motor de búsqueda son innumerables, tanto en indexación como en búsqueda, y elegir unas u otras dependerá del proyecto concreto en el que lo vayamos a utilizar. Además, hay que tener en cuenta qque la implantación de un motor de búsqueda es un proceso de mejora continua, en el que se parte de una configuración inicial, y con el paso del tiempo y mediante el análisis de las búsquedas realizadas por los usuarios, su grado de satisfacción y otros factores esta configuración de partida se va refinando hasta conseguir los resultados deseados.
En Hiberus Digital disponemos de un equipo de expertos en Elasticsearch. Si estás pensando en implantar esta solución en tu empresa no dudes en contactar con nosotros.
¿Quieres más información sobre nuestros servicios de agencia digital y tecnología para ecommerce?
Contacta con nuestro equipo de hiberus digital

Hola buenos días como están?, quería hacerles una consulta al respecto sobre los documentos indexados en los indices que se puedan crear, mi pregunta va mas orientada a los documentos que se ingestan en mayúsculas y con acentos, se que para aplicar búsquedas, podemos utilizar los analyzer y sus multiples combinaciones con los filters y tokenizer, también sé, que con las distintas versiones tenemos otras herramientas llamadas ICU Analysis Plugin, pero existen otras herramientas con las que si yo tengo estos tipos de documentos, al momento de hacer alguna búsqueda me devuelvan resultados pasando el texto completo al momento de buscar, pregunto esto mas quedo por si existen algunas otras manera de aplicar mas herramientas a las búsquedas dentro del elasticsearch.
Gracias por su atencion.