

Debido a la fuerza que está cogiendo el Big Data, el uso de las nubes públicas se ha convertido en un hecho fundamental a la hora de gestionar la información con mayor eficiencia. Si bien existen numerosas empresas grandes que ofrecen servicios destinados a este cometido, nos centraremos en el creado por Google para este análisis.
Qué es Google Cloud Platform
Antes que nada, Google Cloud Platform es la nube pública de Google que nos proporciona herramientas y servicios para trabajar temas de Machine Learning, Networking, Cloud Computing, Big Data o Storage, entre otras. Ésta permite a los desarrolladores poder trabajar de una manera más eficiente mientras que asegura una reducción en los gastos de capital para las empresas. Esto hace que sea una de las mejores plataformas Cloud para explotar y procesar grandes cantidades de datos sin necesidad de disponer de grandes cantidades de capital.
En este artículo nos centraremos en los servicios de analítica y almacenamiento de datos y se tratará de explicar los diferentes formatos que se pueden almacenar en Google Cloud Storage (Storage) y su posterior paso a BigQuery (BigData).


Sobre el servicio de almacenamiento Google Cloud Storage
En primer lugar, Google Cloud Storage es un servicio de almacenamiento de alta durabilidad que, a su vez, se puede extender a cuatro tipos de almacenamiento dependiendo su coste y la frecuencia de uso. No obstante, la principal característica, y en la que nos centraremos, es la capacidad que tiene para almacenar datos de archivos estructurados o semiestructurados, ya sea en formato JSON, AVRO, Parquet o CSV.
Ahora bien, estos formatos que serán analizados se pueden distinguir por la orientación de su almacenamiento. Esto es, ya sea por columnas (Parquet) o por filas (JSON, CSV y AVRO).
Parquet
Comencemos por Parquet. Éste es un formato de archivo gratuito y Open Source basado en el almacenamiento orientado a columnas, lo que permite ahorrar espacio de almacenamiento y asegurar que su compresión sea eficiente. Esto hace que las consultas busquen valores en columnas, en vez de por filas lo que contribuye a que se agilicen las búsquedas que tiendan a usar columnas enteras. Además, admite modelo de datos anidados, lo que supone una importante ventaja sobre otros formatos columnares como ORC.
Apache Avro
Apache Avro, por su parte, es un formato que utiliza JSON para definir los tipos de datos y que es capaz de serializar los datos en un formato binario, lo que lo hace más compacto y eficiente. El hecho de que Avro presente el esquema con el que se han escrito los datos, permite mejorar el rendimiento de escritura de los mismos, consiguiendo que la serialización sea más rápida y viable.
Si comparamos los distintos formatos para cargar datos en BigQuery, Avro tiene ventajas sobre otros formatos como CSV y JSON. En primer lugar, Avro, al presentar un formato binario, permite cargar los datos de manera más rápida, no es necesaria la escritura o la serialización y es más fácil analizar dado que no hay problemas de codificación.
CSV y JSON
En cuanto a los formatos CSV y JSON, hemos visto que son los peores en comparación con los otros dos; sin embargo, vemos que, si los comprimimos, se reducen en mayor proporción que Avro y Parquet. Además, presentan ciertas limitaciones en comparación con el resto de los formatos. Por un lado, los archivos CSV no admiten datos anidados. Sin embargo, una capacidad que está actualmente en preview es el poder ingestar campos de tipo JSON desde un CSV.
Con JSON, por su parte, los datos tendrán que estar delimitados por saltos de línea. Además, BigQuery no admite diccionarios anidados en JSON debido a la falta de información de esquema y a la necesidad de pasar los números a string, si éstos quedan fuera del rango [-253+1, 253-1].
Tanto para JSON como CSV, al utilizar la compresión gzip, BigQuery no es capaz de leer los datos en paralelo. Además, cargar archivos comprimidos será un proceso más lento que subirlos sin comprimir. Aunado a esto, el tamaño máximo de un archivo gzip no podrá superar los 4 GB. Por otra parte, para los formatos de tiempo como DATE o TIMESTAMP, será necesario utilizar un separador de guión.
Tal y como hemos visto, dependiendo del tipo de formato el tamaño de los archivos será uno u otro.
Haciendo una comparativa de almacenamiento
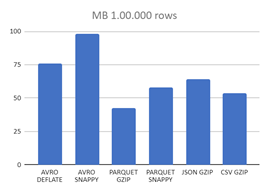
Se ha realizado un estudio, cogiendo registros de un dataset público bigquery-public-data.chicago_crime.crime (8 STRING 8 INTEGER 4 FLOAT 2 BOOLEAN) tomando 5.000, 100.000 y 1.000.000 de registros y se ha comparado el tamaño de los archivos dependiendo del tipo de formato en el que se guarda. Estos son los tamaños en MBs que hemos obtenido.
| 5000 rows | 100000 rows | 1000000 rows | |
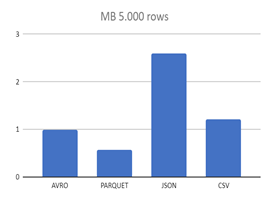
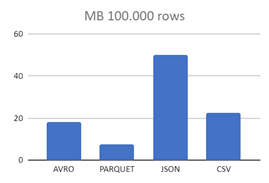
| AVRO | 0,9809 MB | 18,1 MB | 179,2 MB |
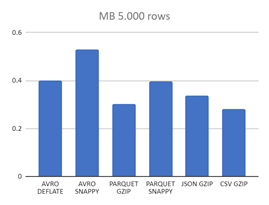
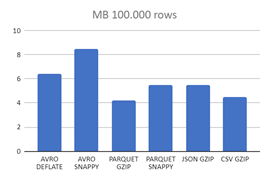
| AVRO DEFLATE | 0,4016 MB | 6,4 MB | 76 MB |
| AVRO SNAPPY | 0,5313 MB | 8,5 MB | 98,3 MB |
| PARQUET | 0,5603 MB | 7,4 MB | 81,1 MB |
| PARQUET GZIP | 0,3013 MB | 4,2 MB | 42,6 MB |
| PARQUET SNAPPY | 0,3954 MB | 5,5 MB | 57,9 MB |
| JSON | 2,6 MB | 50,1 MB | 489,1 MB |
| JSON GZIP | 0,3376 MB | 5,5 MB | 64,3 MB |
| CSV | 1,2 MB | 22,5 MB | 223,4 MB |
| CSV GZIP | 0,2797 MB | 4,5 MB | 53,4 MB |
5000 ROWS
100.000 ROWS
1.000.000 ROWS
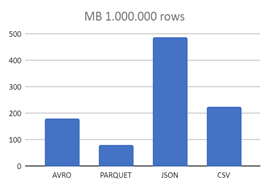
Como podemos ver, los formatos CSV y JSON crecen mucho más rápido de tamaño a medida que aumentan los registros y, tal y como se ve, PARQUET sería la mejor opción que existe, principalmente por su almacenamiento columnar, lo que reduce considerablemente su tamaño.
Por su parte, si nos fijamos en los formatos comprimidos, se comprueba que los tamaños se reducen considerablemente, sobre todo en los formatos JSON y CSV equilibrándose entre los distintos formatos.
Con el fin de darle una visión más empresarial, vamos a analizar los costes que supondría a nivel de empresa. En Google Cloud Storage, existen 4 tipos de almacenamiento cuyas características dependen del coste y de su cantidad de uso. Estos son el Standard, Nearline, Coldline y Archive. Respectivamente, las duraciones mínimas de estos tipos almacenamiento son 0, 30, 90 y 365 días.
A continuación, se muestran los costes por tipo de almacenamiento para la Ubicación UE (Multirregional) en GB/mes.
| Ubicación | Standard Storage | Nearline Storage | Coldline Storage | Archive Storage |
| UE (Multirreg) | $0.026 | $0.010 | $0.007 | $0.004 |
Una vez que tenemos los precios de almacenamiento en Google Cloud Storage y los tamaños de los diferentes formatos, se va a realizar una estimación de los costes que supondría cada formato.
Supongamos el caso hipotético de incorporar al día 5.000.000 de registros con 22 campos como en el ejemplo anterior y utilizando el Standard Storage, podríamos extraer los siguientes datos.
| FORMATO | TAMAÑO / DÍA | PRECIO MES |
| AVRO | 896 MB | $0,68 |
| AVRO DEFLATE | 380 MB | $0,29 |
| AVRO SNAPPY | 491,5 MB | $0,37 |
| PARQUET | 405,5 MB | $0,31 |
| PARQUET GZIP | 213 MB | $0,16 |
| PARQUET SNAPPY | 289,5 MB | $0,22 |
| JSON | 2445,5 MB | $1,86 |
| JSON GZIP | 321,5 MB | $0,24 |
| CSV | 1117 MB | $0,85 |
| CSV GZIP | 267 MB | $0,20 |
A simple vista, los costos para un mes no parecen muy elevados, pero se pueden sacar varias conclusiones como que, entre los formatos sin comprimir, el uso de PARQUET supondría disminuir los costos en un tercio en comparación con archivos CSV y hasta 4 veces con los archivos JSON.
Está claro que los formatos comprimidos van a tener un coste menor; sin embargo, pueden tener otro tipo de desventajas como un mayor tiempo de carga de los datos o comprobar que algunos entornos, como Apache Spark, pudieran soportar esos formatos.
En Hiberus contamos con una unidad especializada en servicios de Data & Analytics formada por un equipo de profesionales con amplio expertise en en tecnología, análisis de datos e innovación. Somos expertos en Big Data, Machine Learning, Business Intelligence 2.0, y Business Intelligence y Analytics tradicional. Descubre todo lo que podemos hacer por ti.
¿Quieres más información sobre nuestros servicios de Data & Analytics?
Contacta con nuestro equipo de expertos en Data & Analytics
