

¿Cómo se puede aumentar el conocimiento de los LLM con datos con los que no han sido entrenados? La Retrieval-Augmented Generation (RAG) es el camino a seguir. En este blog explicaremos qué significa RAG y, por supuesto, cómo funciona.
Digamos que tienes tu propio conjunto de datos, por ejemplo, documentos de texto de tu empresa. ¿Cómo puedes hacer que ChatGPT y otros LLM los conozcan y respondan a tus preguntas?
Aquí la respuesta: no te preocupes, se puede hacer fácilmente en los siguientes cuatro pasos:
- Embedding: incrusta tus documentos con un modelo de incrustación como text-embedding-ada-002 de OpenAI o S-BERT. Incrustar un documento significa transformar sus frases, palabras o trozos de las palabras en un vector de números. La idea es que las frases que son similares entre sí deben estar cerca en términos de distancia entre sus vectores y las frases que son diferentes deben estar más lejos.
- Vector Store: una vez que tienes una lista de números, puedes almacenarlos en un almacén vectorial como ChromaDB, FAISS, o Pinecone. Un almacén vectorial es como una base de datos, pero, como su nombre indica, indexa y almacena incrustaciones vectoriales para su rápida recuperación y la búsqueda de similitudes.
- Consulta: ahora que tu documento está incrustado y almacenado, cuando hagas una pregunta específica a un LLM, este incrustará tu consulta y encontrará en el almacén de vectores las frases que más se acerquen a tu pregunta en términos de semejanza de coseno, por ejemplo.
- Respuesta a la pregunta: una vez encontradas las frases más parecidas, se suman en la consulta y ¡listo! Ahora, los LLM son capaces de responder a preguntas concretas sobre datos con los que no han sido entrenados, sin necesidad de reentrenamiento o fine-tuning. ¿No es genial?
Pushing Boundaries
En mi última entrada de blog titulada Ask Your Own Data, aumentamos el conocimiento de ChatGPT, desplegado en Azure, utilizando datos privados para hacerlo más factible. En otras palabras, implementamos una aplicación RAG en la que se emplearon dos modelos comerciales de Azure OpenAI, en nuestro caso, el modelo ada-embeddings-001 para embeddings y GPT-3.5 Turbo, que genera respuestas basadas en preguntas o consultas del usuario y contexto relevante. Este contexto relevante consiste en documentos recuperados a partir de un paso de búsqueda mediante búsqueda semántica.
Una desafortunada realidad es que este servicio no es gratuito. En otras palabras, se cobra por cada token generado por el modelo, que es esencialmente uno de los inconvenientes de los modelos comerciales y de código cerrado. Lo ideal sería que la IA fuera de código abierto y se democratizara, como ha señalado por Clem Delangue, CEO de Hugging Face: Es increíblemente difícil empezar sin modelos y conjuntos de datos abiertos.
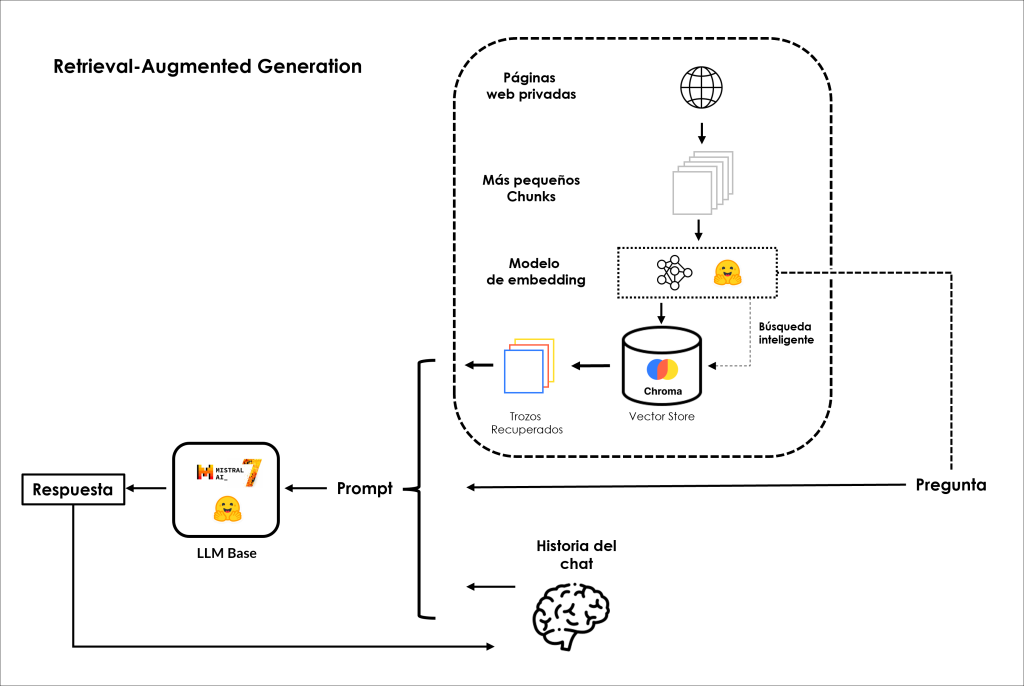
Pero calma, aún no lo hemos dicho todo; ¡abrochaos los cinturones! Ahora nos embarcaremos en un viaje de codificación de alta velocidad para demostrar cómo puedes construir un sistema RAG completamente libre utilizando modelos de código abierto alojados en el Hugging Face Model Hub y codificar cada componente en su siguiente arquitectura:
Instalaciones
Estas líneas de código están instalando varias librerías Python y paquetes usando el gestor de paquetes pip, junto con la bandera –quiet la cual se usa para reducir la cantidad de salida mostrada durante el proceso de instalación, haciéndolo menos ruidoso.
Importaciones
En el siguiente script, importamos una amplia gama de bibliotecas y módulos para tareas avanzadas de procesamiento del lenguaje natural y generación de texto. Esencialmente, estamos configurando un entorno para trabajar con modelos de lenguaje, incluyendo modelos Hugging Face, así como diversas herramientas y utilidades para el manejo y procesamiento de datos de texto.
Importamos principalmente PyTorch para capacidades de aprendizaje profundo y Gradio para construir interfaces interactivas de modelos ML. Además, importamos módulos de la biblioteca LangChain, que incluye plantillas para crear prompts, varios modelos de cadena para la comprensión y generación de lenguaje, text embeddings y cargadores de documentos. Nuestro código también integra la potente biblioteca Transformers, que permite el uso sin problemas de los modelos de última generación de Hugging Face para una amplia gama de aplicaciones de PLN.
LLM Base
Mistral-7b desarrollado por Mistral AI está arrasando en el panorama de los LLM de código abierto. Este nuevo LLM de código abierto supera a LLaMA-2 en muchas pruebas comparativas, como ilustra la siguiente imagen extraída de su documento:
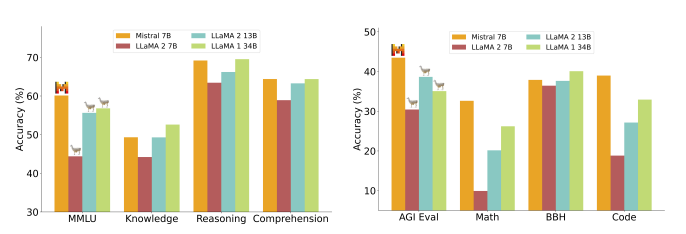
Fuente: Cornell University
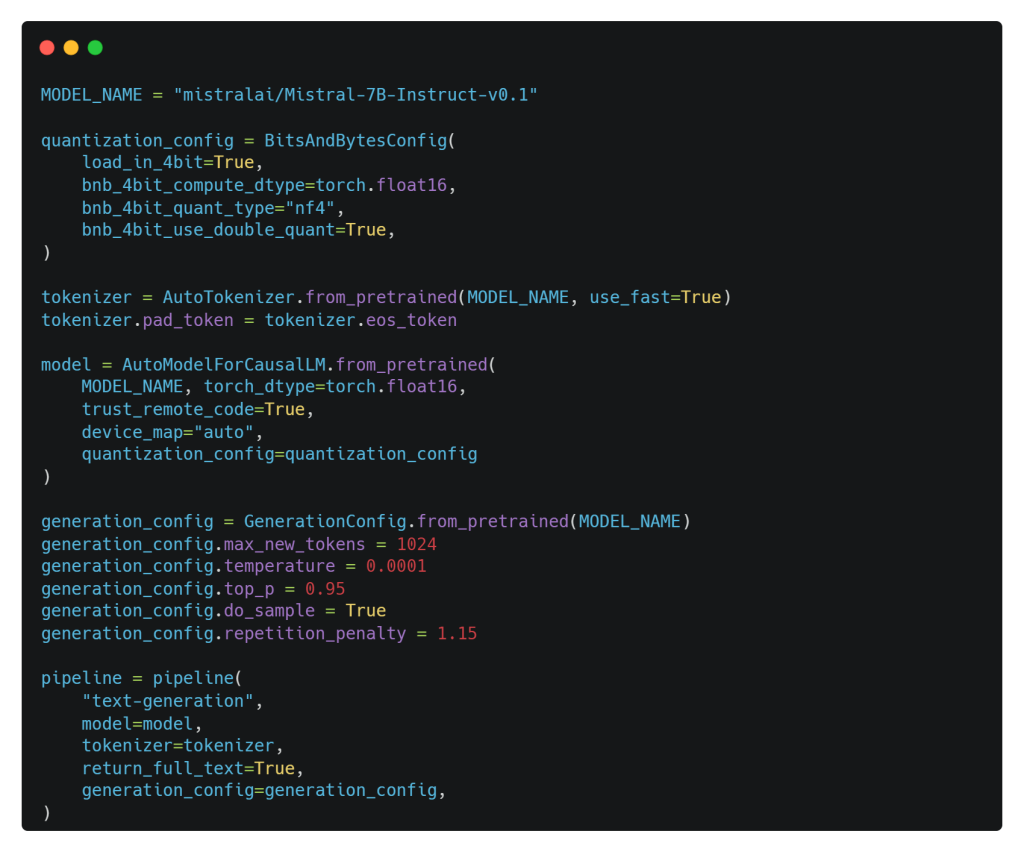
El siguiente fragmento de código se configura un proceso de generación de texto utilizando un LLM base, Mistral-7b desarrollado por Mistral AI, instruye al modelo de lenguaje preentrenado, lo configura con ajustes de cuantización, tokenización y parámetros de generación, y crea un proceso que puede utilizarse para generar texto basado en el LLM Mistral-7b y las configuraciones. Vamos a desglosar lo que sucede:
- quantization_config = BitsAndBytesConfig(…): Aquí se define una configuración de cuantización utilizando BitsAndBytesConfig. La cuantificación es una técnica utilizada para reducir los requisitos de memoria y computación de los modelos de aprendizaje profundo, normalmente mediante el uso de menos bits, 4 bits en nuestro caso para representar los parámetros del modelo.
- tokenizer = AutoTokenizer.from_pretrained(…): Esta línea inicializa un tokenizador para el modelo Mistral-7b, permitiéndole preprocesar datos de texto para introducirlos en el modelo.
- model = AutoModelForCausalLM.from_pretrained(…): Esto inicializa el modelo de lenguaje Mistral-7b pre-entrenado para el modelado causal del lenguaje. El modelo se configura con varios parámetros, incluyendo la configuración de cuantización, que se estableció anteriormente.
- generation_config = GenerationConfig.from_pretrained(…): Se crea una configuración de generación para el modelo, especificando varios parámetros relacionados con la generación, como el número máximo de tokens, la temperature para el sampling, el top-p sampling y la repetition penalty.
- pipeline = pipeline(…): Por último, se crea una línea de generación de texto utilizando la función pipeline. Esta tubería se configura para la generación de texto, y toma el modelo pre-entrenado, el tokenizer, y la configuración de generación como entradas. Está configurado para devolver salidas de texto completo.
HuggingFacePipeline es una clase que permite ejecutar modelos Hugging Face localmente. Se utiliza para acceder y utilizar una amplia gama de modelos ML pre-entrenados alojados en el Hugging Face Model Hub. En nuestro caso, la utilizaremos dentro de nuestro entorno LangChain para interactuar con los modelos de Hugging Face como local wrapper. Sin embargo, cuando se trabaja con HuggingFacePipeline, se recomienda la instalación de xformer para una implementación de atención más eficiente en memoria. Por eso lo hemos instalado más arriba.

¡Vamos a divertirnos un poco! Antes de conectar nuestro LLM base, Mistral-7b, a nuestros datos privados. En primer lugar, hagámosle algunas preguntas generales. Por supuesto, responderá basándose en los conocimientos generales adquiridos durante el preentrenamiento.


¡Muy poderoso! Pero…, ¿qué pasaría si le hacemos una pregunta sobre la que no tenga conocimientos? Probablemente porque no recibió esta información durante su fase de preentrenamiento. Por ejemplo: el Ecosistema GenIA puesto en marcha por Hiberus.


¡Vaya! Esta no es la respuesta esperada. Esto se debe a que Mistral-7b LLM nunca ha visto ninguna información sobre el GenIA Ecosystem durante su preentrenamiento. Sin embargo, prometo guiarte para obtener la respuesta correcta en las próximas secciones.
Embeddings
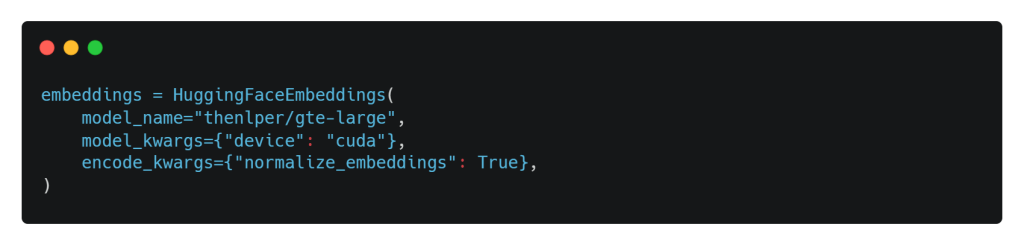
Después de establecer nuestro LLM base, es hora de establecer un modelo de embedding. Como sabes, cada documento debe convertirse en un vector de embedding para permitir la búsqueda semántica utilizando la consulta del usuario, que también debe incrustarse. Para ello, utilizaremos el modelo de incrustación GTE entrenado por Alibaba DAMO Academy y alojado en Hugging Face. Cabe destacar que este modelo es gratuito y potente. Para llevar a cabo nuestra tarea, utilizaremos la clase HuggingFaceEmbeddings, un pipeline wrapper local para interactuar con el modelo GTE alojado en Hugging Face Hub.
Prompt Template
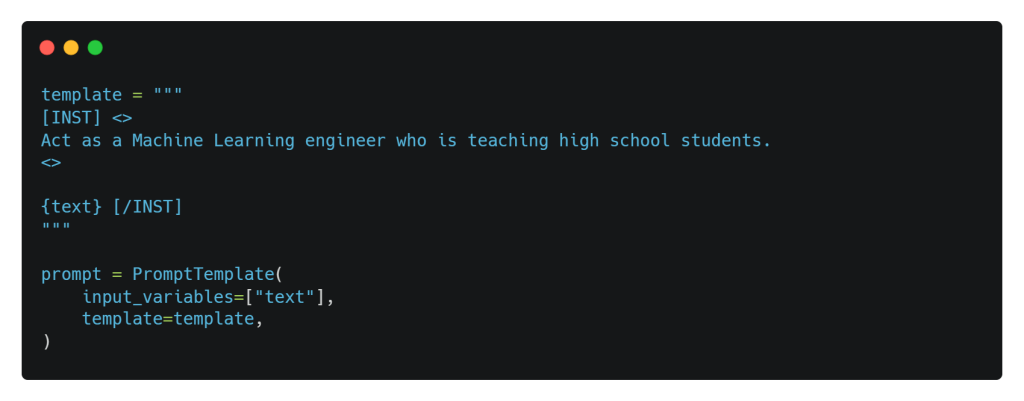
¿Sabías que podemos dar una identidad a nuestro LLM base y hacer que se comporte según nuestras preferencias, controlando la salida del modelo sin especificarlo todo explícitamente en la consulta o prompt del usuario? Esto se consigue mediante prompt templates, que son recetas predefinidas para generar avisos para modelos lingüísticos. En otros contextos, se puede dar una identidad a un LLM mediante un Mensaje de sistema.
Utilizamos PromptTemplate para crear un prompt estructurado. Una plantilla puede incluir instrucciones, n-shot ejemplos y contexto específico y preguntas adecuadas para una tarea en particular.
Volvamos a consultar nuestro modelo.


Carga de datos
Para obtener una respuesta precisa a nuestra pregunta anterior, What is the hiberus GenIA Ecosystem? tendremos que conectar nuestro LLM con información sobre el Ecosistema GenIA.
¡Estamos de suerte! Hay dos páginas web que tienen la clave para entender el Ecosistema GenIA. Estas páginas web se encuentran directamente en el sitio web de Hiberus. Son como tesoros de información, que ofrecen una visión en profundidad de este innovador ecosistema recientemente lanzado por hiberus.
Ahora, puede que te estés preguntando cómo proceder con esta misión de carga de datos. Afortunadamente, tenemos un script que está a la altura de la tarea. Echémosle un vistazo: El UnstructuredURLLoader es tu varita mágica para obtener la información que buscas. Una vez que ejecutemos este script, tendrás a tu disposición una colección de documentos, cada uno con una pieza del puzzle GenIA. Básicamente, dos documentos, uno para cada enlace.

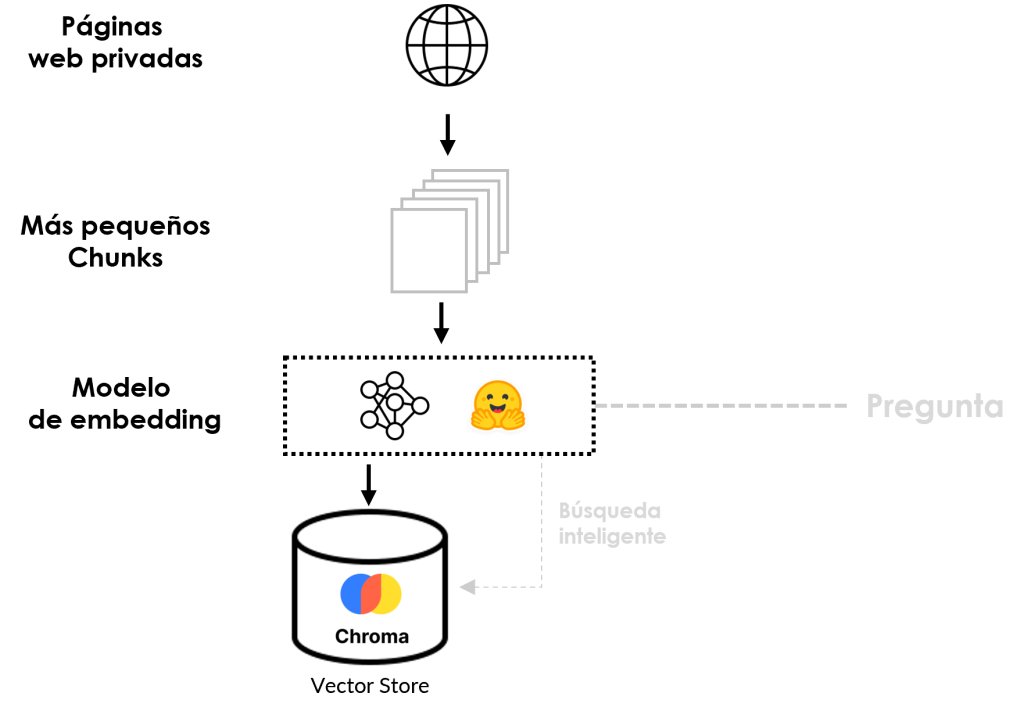
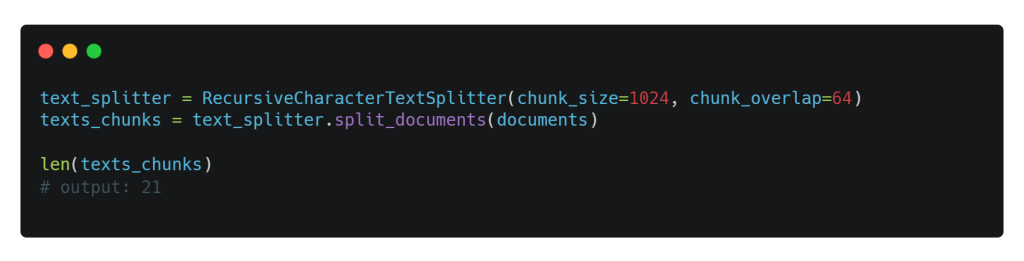
Ahora tenemos dos documentos de gran tamaño repletos de datos, y eso podría superar la ventana de contexto de nuestro Mistral-7b LLM. Para mantener todo bajo control, vamos a dividirlos en 21 documentos más pequeños o chunks, cada uno con un límite de 1024 tokens. Además, hemos fijado el tamaño de chunk overlap en 64 para garantizar que haya cierta continuidad de contexto entre trozos consecutivos. Permanece atento al próximo paso en la ingesta de esta aventura de datos.
Ingesta de datos
Una vez que tenemos nuestros trozos de datos manejables, el siguiente paso es incrustarlos e indexarlos en Chromadb, nuestro vector store. ¿Y lo mejor? Es muy fácil y se puede hacer con una sola línea de código.

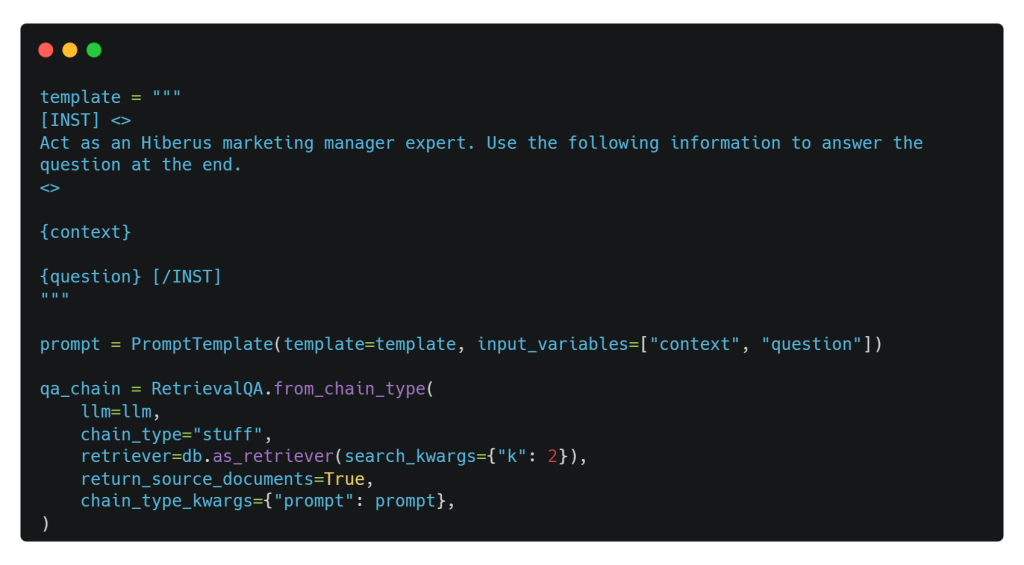
Una vez indexados nuestros datos, en el script que aparece a continuación, ajustamos nuestra plantilla de consulta para que se adapte a nuestras necesidades y damos a nuestro modelo de RAG la personalidad de un experto en gestión de marketing.
Además, para combinar nuestro LLM con las capacidades de recuperación de la base de datos vectorial, utilizamos el componente crucial de encadenamiento RetrievalQA con k=2. Esta configuración garantiza que el recuperador produzca dos fragmentos relevantes, que el LLM utiliza para formular la respuesta cuando se presenta una pregunta.
Querying
¡Estupendo! Nuestro sistema GAR está listo para responder a tus preguntas. Así que vamos a sumergirnos en él y a hacerle algunas preguntas, incluida la que nos hemos saltado antes. ¡Allá vamos!


¡De acuerdo! Hagamos otra pregunta para conocer las razones detrás de la creación del Ecosistema GenIA.
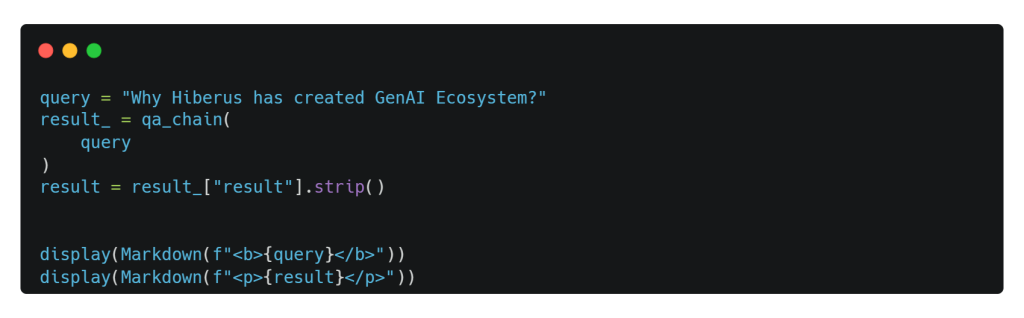

Et voilá! Tenemos grandes respuestas para ambas preguntas, incluida la que se nos pasó antes. Cabe señalar que podemos imprimir las source documents o documentos de referencia a partir de las cuales el LLM ha generado las respuestas. El escenario ahora es tuyo; considera la siguiente línea como el punto de partida para tu exploración.

Follow-Up Q/A
En el mundo real, el chat de seguimiento es útil, especialmente con los asistentes conversacionales de IA. Permite a los usuarios entablar conversaciones naturales con el modelo al mismo tiempo que conserva el historial de chat en el contexto del modelo. Esto significa que los usuarios pueden referirse implícitamente a algo de lo que han hablado en mensajes de chat anteriores o sacar a colación temas sobre los que han charlado en el pasado. Es como charlar amistosamente con un amigo de la inteligencia artificial que te recuerda.
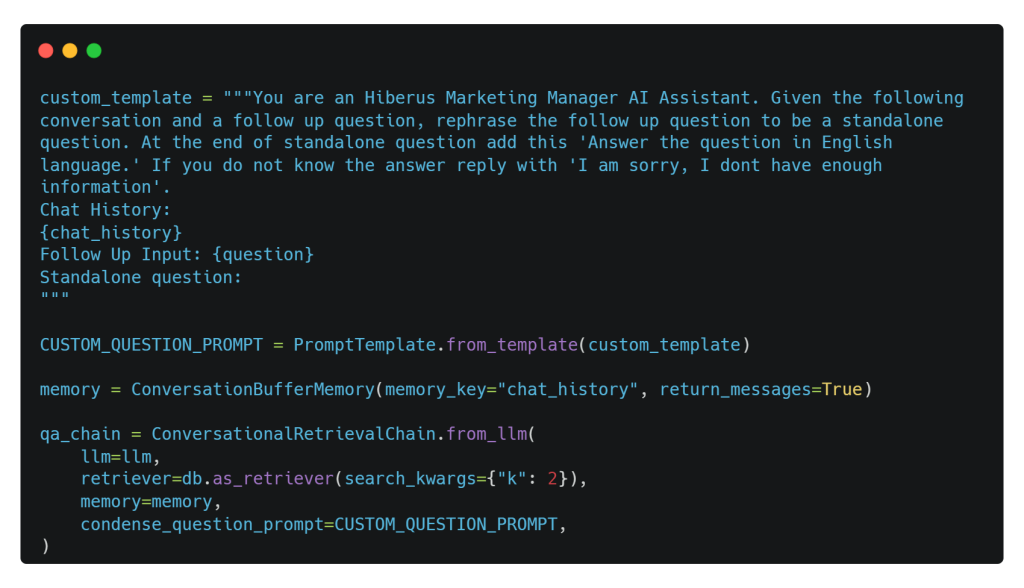
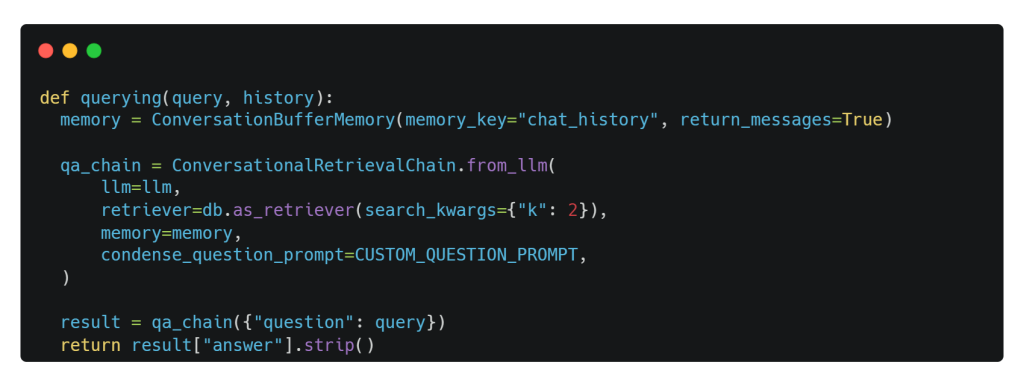
Para que esto suceda, primero hacemos algunos ajustes en la plantilla de avisos. A continuación, utilizamos ConversationBufferMemory para almacenar la conversación en memoria y recuperar los mensajes más tarde. Por último, empleamos el componente de encadenamiento ConversationalRetrievalChain para combinar nuestro LLM, Mistral-7b, con la base de datos vectorial y el historial de chat. Todo ello, para mejorar la experiencia de conversación del usuario.

Pregunta nº 1


Pregunta nº 2


Si todavía tienes dudas sobre tu historial de chat, puedes ejecutar estos fragmentos de código para echarle un vistazo a tus preguntas en HumanMessages y a las respuestas del modelo en AIMessages. Esto te dará una visión clara de la conversación y te ayudará a resolver cualquier duda que puedas tener. ¡Es una forma práctica de hacer un seguimiento de la interacción!

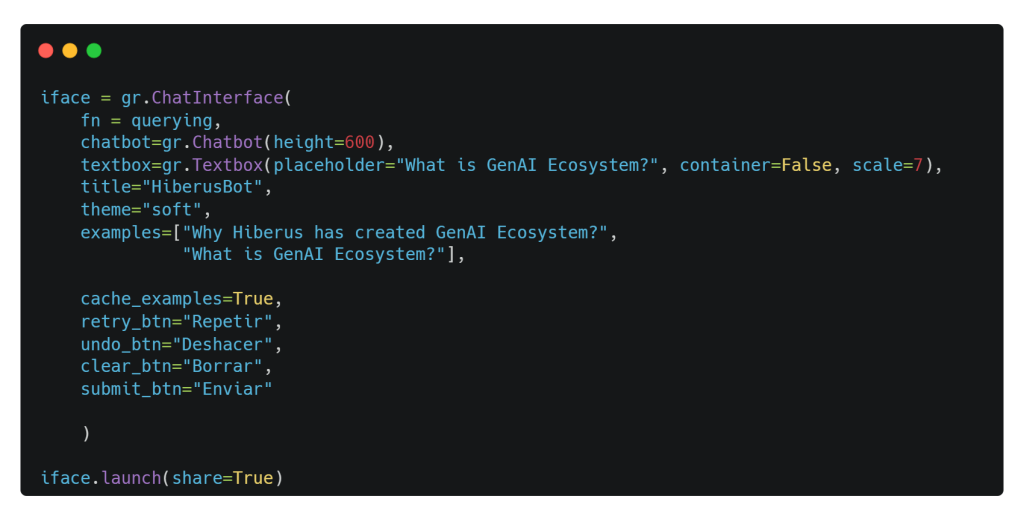
Gradio Chat UI
Gradio es tu billete rápido para demostrar tu modelo RAG con una interfaz web fácil de usar a la que cualquiera puede acceder desde cualquier lugar. Funciona así: hemos creado una función ingeniosa llamada querying(). Toma query como entrada principal, junto con un argumento falso llamado history para resolver un problema menor. Cuando se activa esta función, devuelve la respuesta generada por nuestro modelo superestrella, Mistral-7b. ¡Así de sencillo!
Lanza la aplicación web de Gradio.
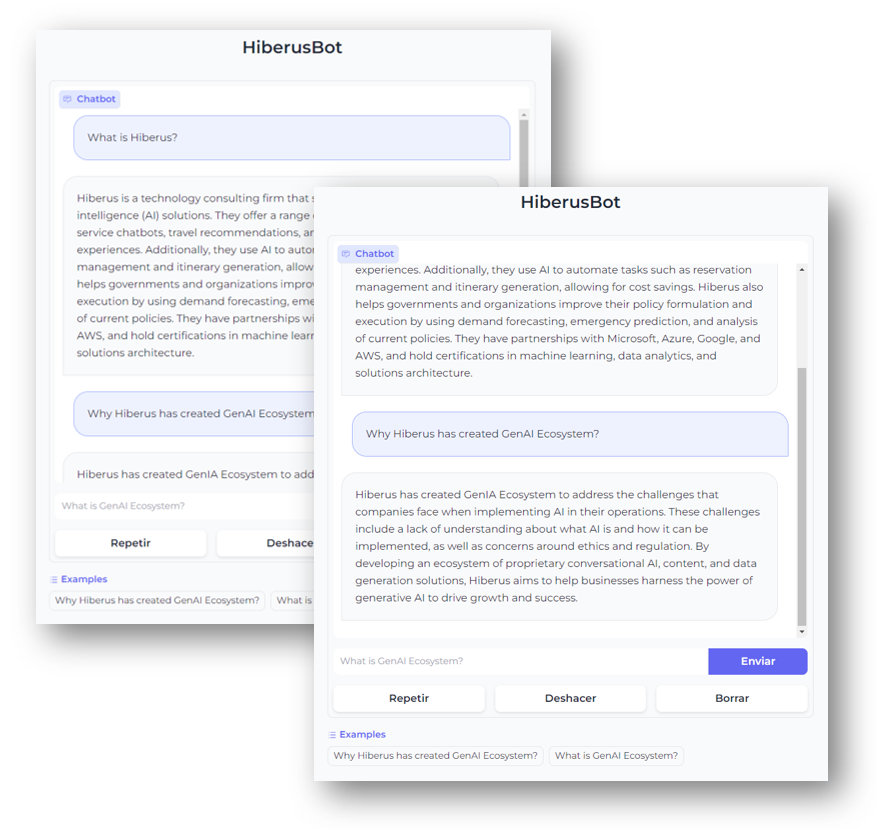
Tu interfaz de usuario final debería verse como las siguientes imágenes, ¿no es asombroso?
Conclusión
Las aplicaciones RAG están poniendo patas arriba el panorama de la IA, gracias a los saltos dados por los grandes modelos lingüísticos. Herramientas como LangChain, LlamaIndex y marcos similares están allanando el camino para el rápido desarrollo de aplicaciones que aprovechen todo el potencial de los LLM. Esto incluye aumentar los conocimientos de los LLM con datos privados como PDF, URL, vídeos, etc., datos con los que nunca se han encontrado durante su entrenamiento inicial.
De hecho, no hemos mencionado que también se puede crear una aplicación RAG utilizando datos de todo Internet, no sólo de unos pocos enlaces o páginas web… Para ello, primero hay que utilizar un retriever que obtenga dinámicamente las páginas web pertinentes de Internet, utilizando, por ejemplo, las Google Search APIs o cualquier otra alternativa. A continuación, puede utilizar un re-ranker para ordenar y clasificar el contenido de todas las páginas web recuperadas, proporcionando al LLM el contexto relevante necesario para generar la respuesta perfecta para una consulta determinada.
¿Y lo mejor? RAG también puede implementarse de forma segura en la nube. Existen opciones como OpenAI On Your Data dentro de Azure, Amazon Bedrock y toda una serie de servicios en GCP. ¡Es una revolución en IA con posibilidades ilimitadas!
Estad atentos, ¡y hasta pronto!
En hiberus creemos que la IA se va a convertir en una herramienta imprescindible en todos los campos y sectores en un futuro próximo. Por eso hemos creado la newsletter Behind the AI en la que te contamos todas las novedades y hechos relevantes que debes conocer para no perderte nada sobre Inteligencia Artificial.

¿Quieres aprovechar el poder de la IA Generativa para impulsar tu negocio? Contamos con un equipo de expertos en IA Generativa y Data que han desarrollado GenIA Ecosystem, un ecosistema de soluciones propias de IA conversacional, generación de contenido y data adaptadas a las necesidades de cada mercado y cliente. Contacta con nosotros y estaremos encantados de ayudarte.
¿Quieres más información sobre nuestros servicios de IA Generativa?
Contacta con nuestro equipo de expertos en IA Generativa
«Great insights on RAG! It’s fascinating to see how embedding and vector storage can make LLMs much more powerful. The integration with open-source models is especially encouraging for developers looking to democratize AI. Thanks for sharing!»