

Actualmente, la IA generativa está impresionando al mundo entero con su capacidad para crear imágenes, códigos y diálogos realistas. Sin duda, ChatGPT, usado por millones de personas actualmente, ha supuesto un gran avance en este campo. Sin embargo, aunque es muy potente en lo que respecta al conocimiento general, sólo conoce la información con la que fue entrenada, es decir, los datos que encontramos disponibles en Internet hasta 2021. Así pues, no conoce tus datos privados ni las fuentes de datos más recientes.
En el mismo contexto, los Large Language Models (LLMs) son excelentes para muchas cosas (si no estás familiarizado con los LLM, no te preocupes, puedes ver este increíble vídeo de Kate Soule de IBM). No obstante, como decíamos antes, no están especialmente entrenados para recuperar información actual o privada. Por lo tanto, para mejorarlos en ese aspecto, primero debemos proporcionarles información recuperada mediante la búsqueda de documentos similares (similarity search). Esto los hace más conscientes y les da una mayor capacidad para proporcionar al modelo información actualizada, sin necesidad de volver a entrenar a estos modelos masivos. Esto es precisamente lo que es un LLM mejorado por recuperación. De hecho, este post esbozará con precisión la creación de un modelo de este tipo y dilucidará los pasos a seguir en cuanto a su optimización.
Por lo tanto, el presente post trata el tema de cómo añadir datos privados a los LLMs, y de cómo crear un sistema de Retrieval-Augmented Generation (RAG) que utiliza el conocimiento de ChatGPT sobre un corpus de datos específico, actual o privado mediante herramientas de ingeniería de pronóstico como LangChain y LlamaIndex para generar respuestas sobre datos privados. No te pierdas nada; tenemos una BONIFICACIÓN muy chula para ti al final.
¿Qué es LlamaIndex?
LlamaIndex simplifica las aplicaciones basadas en LLMs. Los LLMs, como GPT-4, Falcon y LLaMa2, llegan preentrenados en vastos conjuntos de datos públicos, lo que desbloquea las impresionantes capacidades de procesamiento del lenguaje natural. Sin embargo, como es obvio, carecen de datos privados específicos.
Con LlamaIndex, sin embargo, podemos incorporar sin problemas datos de API, bases de datos, archivos PDF y mucho más mediante conectores adaptables. Estos datos se optimizan para los LLMs mediante representaciones intermedias. Esto permite realizar, sin esfuerzo, consultas e interacciones en lenguaje natural a través de motores de consulta, interfaces de chat y agentes de datos potenciados por los LLM. Así, el LLM puede acceder a una gran cantidad de datos privados y comprenderlos sin necesidad de reentrenar el modelo para obtener nueva información.
LlamaIndex ofrece un completo conjunto de herramientas para aplicaciones basadas en lenguaje. Además, se pueden aprovechar los cargadores de datos y las herramientas de agente Llama Hub, que permiten crear aplicaciones complejas con diversas funcionalidades.
¿Qué es LangChain?
LangChain es un marco para desarrollar aplicaciones basadas en modelos lingüísticos. Permite aplicaciones que son:
- Conscientes sobre los datos: conectan un modelo lingüístico a otras fuentes de datos.
- Agentic: permiten a un modelo lingüístico interactuar con su entorno.
Estas son algunas de las principales ventajas de LangChain:
- Componentes: herramientas abstractas para trabajar con modelos lingüísticos, junto con una colección de implementaciones para cada herramienta. Estos componentes modulares son fáciles de usar y pueden emplearse independientemente del marco LangChain.
- Off-the-shelf chains: un conjunto estructurado de componentes para realizar tareas específicas de nivel superior.
La disponibilidad de chains prediseñadas facilita la iniciación. Para aplicaciones complejas y escenarios matizados, los componentes permiten personalizar sin esfuerzo las chains existentes o crear otras nuevas.
En este tutorial, utilizaremos LangChain únicamente para inicializar nuestros modelos LLM y embedder procedentes de Azure OpenAI.
¿Cómo funciona RAG?
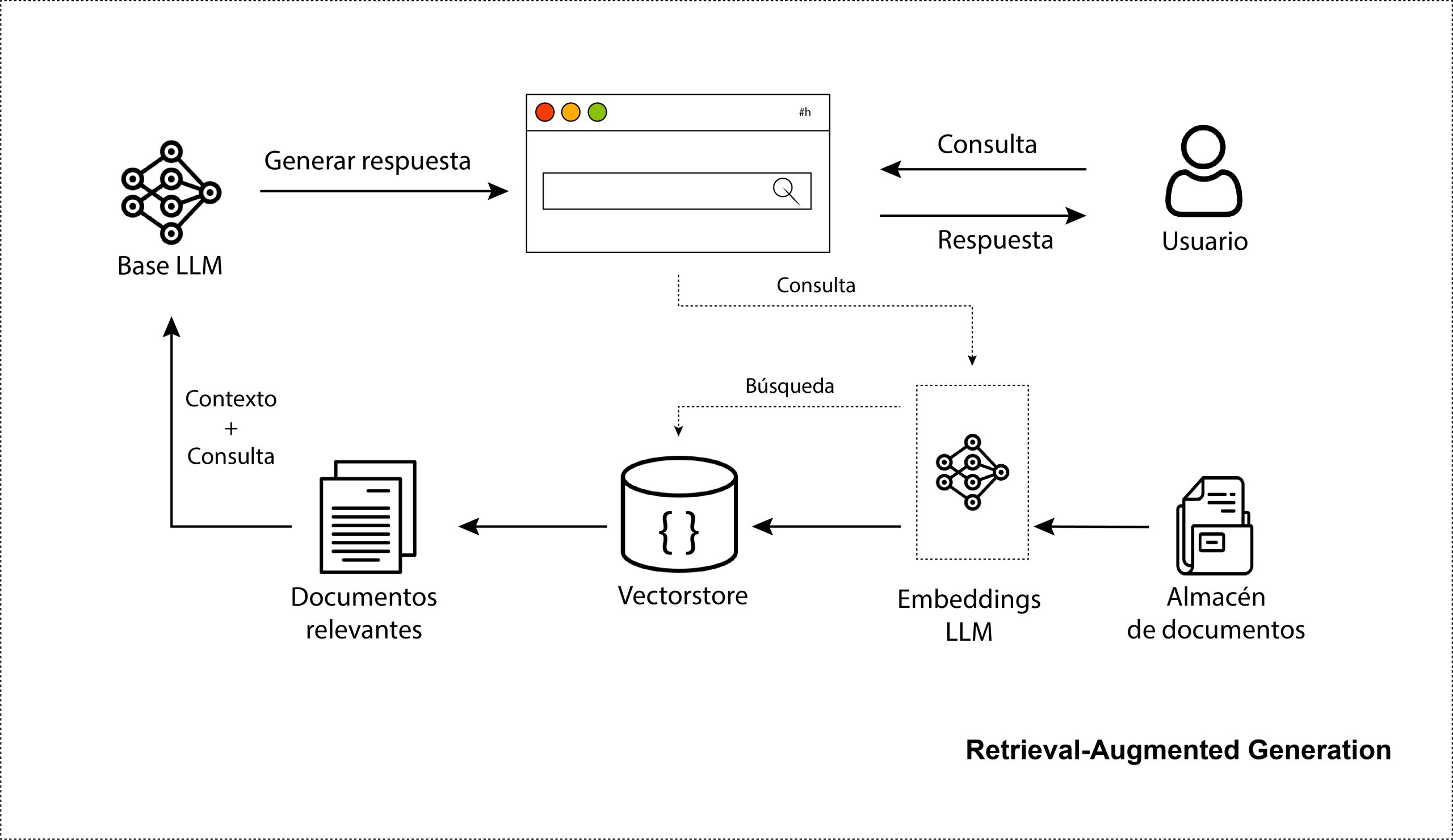
RAG consiste en integrar la potencia de la recuperación (o búsqueda) en un LLM base. En general, consta de un recuperador, que obtiene fragmentos de documentos relevantes de un gran corpus de información externa, y un LLM, que produce respuestas a partir de esos fragmentos, como se ilustra en el siguiente diagrama:
Instala las librerías necesarias
Antes de conducir, hay que ponerse el cinturón de seguridad; del mismo modo aquí, antes de hacer nada, asegúrate de tener instalado el paquete OpenAI y también LlamaIndex, LangChain y PyPDF. Necesitas instalar PyPDF para habilitar las funciones integradas de LlamaIndex para leer y convertir archivos PDF.

Importaciones
En el siguiente fragmento de código, importamos el paquete openai junto con las clases y funciones incorporadas de los paquetes LlamaIndex y LangChain. Además, importamos el paquete os para definir algunas environment variables que configuraremos más adelante.
Utilizaremos Azure OpenAI Studio, para lo cual necesitamos acceder a la API de OpenAI. Empecemos por configurar los entornos de las variables para configurar el acceso a la API OpenAI alojada en Azure. Esto implica incluir la clave API, versión, tipo y URL base que son esenciales para que el script de Python se comunique efectivamente con la API.
Cabe destacar que la API OpenAI del sitio web puede integrarse de forma similar, requiriendo la configuración de una única variable de entorno, OPENAI_API_KEY.

Service Context
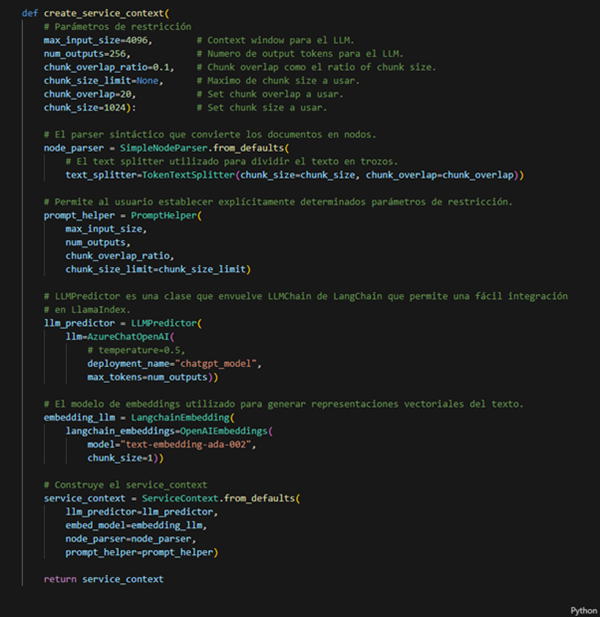
En la siguiente función, después de establecer varios parámetros de restricción, incluyendo max_input_size y num_outputs, para tratar eficazmente con las limitaciones de token de ventana de contexto del LLM definimos un prompt helper, PromptHelper. Este ayudante calcula el tamaño de contexto disponible partiendo del tamaño de la ventana de contexto del LLM y reservando espacio para la plantilla de aviso y la salida.
El prompt helper proporciona una utilidad para reempaquetar trozos de texto (recuperados del índice) para aprovechar al máximo la ventana de contexto disponible (y reducir así el número de llamadas LLM necesarias), o truncarlos para que quepan en una sola llamada LLM. De hecho, puedes sentirte libre de ajustar las opciones de configuración para alinearlas con tus necesidades.
Además, utilizamos la clase AzureChatOpenAI para crear nuestro modelo de chat basado en GPT-3.5 Turbo. En particular, chatgpt_model sirve como nombre de implementación para GPT-3.5 Turbo en Azure OpenAI Studio. Asimismo, utilizamos la clase OpenAIEmbeddings para construir nuestro incrustador, aprovechando el potente modelo de incrustación de OpenAI text- embedding-ada-002.
Por último, construimos ServiceContext, que agrupa los recursos más utilizados durante las fases de indexación y consulta de un proceso LlamaIndex. Lo empleamos para configurar tanto la configuración global como la local.
Carga de datos
Como nos encanta conectar la investigación con la producción, utilizaremos el artículo Chinchilla de Jordan Hoffmann et al. de DeepMind como nuestros datos privados y haremos algunas preguntas interesantes sobre sus principales conclusiones. Al hablar del artículo sobre Chinchilla, nos viene a la mente el modelo de parámetros Chinchilla-70B entrenado como modelo óptimo de cálculo con 1,4 billones de fichas. Las conclusiones del artículo sugieren que este tipo de modelos se entrenan de forma óptima escalando de manera equitativa tanto el tamaño del modelo como los tokens de entrenamiento. Utiliza el mismo presupuesto de cálculo que Gopher pero con 4 veces más datos de entrenamiento.

Data ingestion
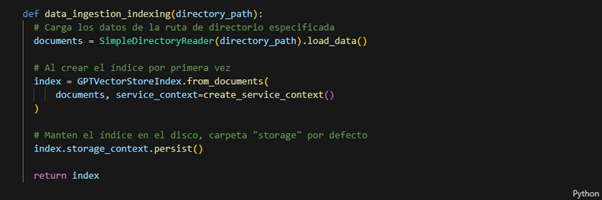
En la etapa de ingestión de datos, empezamos creando un directorio llamado data que contiene sólo un archivo PDF, el archivo PDF del papel Chinchilla. Luego usamos el SimpleDirectoryReader para leerlo y, posteriormente, convertirlo en un índice usando el GPTVectorStoreIndex.
De hecho, para indexar nuestros documentos incrustados, utilizamos LlamaIndex GPTVectorStoreIndex, que crea vectores numéricos a partir del texto utilizando palabras incrustadas y recupera los documentos relevantes basándose en la similitud de los vectores cuando indexamos los documentos.
La recreación del índice es un proceso que consume mucho tiempo, pero puede evitarse guardando el contexto. El siguiente comando guarda el índice en el directorio por defecto ./storage**.
Ejecutar una consulta
Para la configuración global podemos establecer un contexto de servicio como el «por defecto global» que se aplica a toda la tubería de LlamaIndex.

Nuestro enfoque consiste en formular una pregunta general sobre el documento y obtener una respuesta utilizando vquery_engine.query. Además, formulamos una serie de preguntas de seguimiento relacionadas utilizando query_engine.chat sin proporcionar contexto adicional. En las próximas secciones nos explayaremos sobre estas dos opciones. Ahora vamos a iniciar nuestro index. Por favor, asegúrate de que has movido el papel de chinchilla a la carpeta data antes de ejecutar el siguiente fragmento:

Q&A
Una vez que nuestros datos privados han sido indexados, podemos empezar a hacer preguntas utilizando as_query_engine(). Esta función permite hacer preguntas sobre información específica dentro del documento y recibir la respuesta correspondiente con la ayuda del modelo GPT-3.5 Turbo de OpenAI.



¡Genial! Como puede verse, el modelo LLM ha respondido con precisión a la consulta. Buscó en el índice y encontró la información relevante, luego la escribió de una manera similar a la humana. Un punto adicional a destacar es que hemos utilizado display_response() para mostrar la respuesta en un formato HTML bien estructurado.
Otro aspecto desafortunado de ChatGPT es que, cuando le planteamos las mismas preguntas, parece desconocer la actualidad mundial. A continuación encontrarás su divertida respuesta:
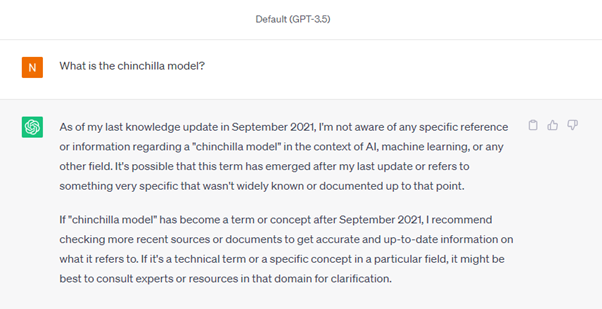

El modelo sabe a qué palabra se refiere it y no es capaz de responder. Sin embargo, esto ocurrirá con frecuencia en el contexto de las preguntas de seguimiento. Abordaremos esta cuestión en la próxima sección.

Incluso puede comprobar el archivo de referencia y la página de la respuesta como se muestra aquí:

Chatbot
En lugar de Q&A, también podemos utilizar LlamaIndex para crear un Chatbot personal que soporte follow up de preguntas sin dar contexto adicional. Sólo tenemos que inicializar el índice con la función as_chat_engine().



Bonus
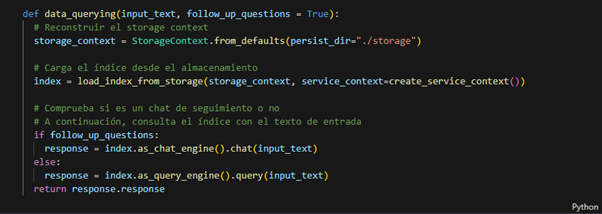
Como fan de 🤗 Hugging Face y su ecosistema, no puedo concluir este blog sin hablar de él de alguna manera. De hecho, nuestro bono consiste en crear una interfaz sencilla utilizando Gradio de 🤗 para chatear con nuestro sistema. Para ello, implementamos una función que reconstruye el contexto de almacenamiento, carga el índice y lo consulta con un texto de entrada.

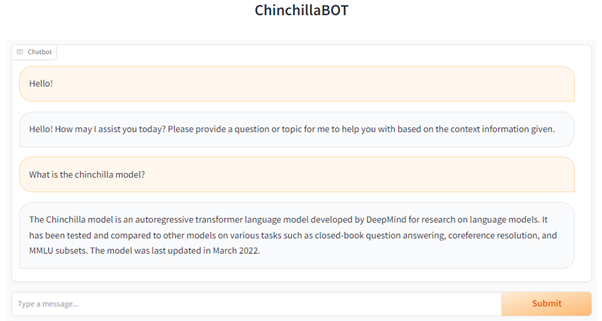
El código completo está disponible en este repositorio de GitHub.
Conclusión
Nuestra aventura ha llegado a su fin, pero aquí van algunas conclusiones. En este tutorial, hemos visto que LangChain y LlamaIndex proporcionan potentes conjuntos de herramientas para construir aplicaciones inteligentes basadas en la RAG que combinan las fortalezas de los grandes modelos lingüísticos con bases de conocimiento personalizadas. Permiten crear un almacén indexado de datos específicos del dominio y aprovecharlo durante la inferencia para proporcionar un contexto relevante al LLM con el fin de generar respuestas de alta calidad en un lenguaje similar al humano. Sin embargo, estamos seguros de que sólo hemos cubierto algunos aspectos básicos, pero veremos más cosas interesantes sobre RAG en el futuro. ¡Estad atentos!
En Hiberus Tecnología creemos que la IA se va a convertir en una herramienta imprescindible en todos los campos y sectores en un futuro próximo. Por eso hemos creado la newsletter Behind the AI en la que te contamos todas las novedades y hechos relevantes que debes conocer para no perderte nada sobre Inteligencia Artificial.

¿Quieres aprovechar el poder de la IA Generativa para impulsar tu negocio? Contamos con un equipo de expertos en IA Generativa y Data que han desarrollado GenIA Ecosystem, un ecosistema de soluciones propias de IA conversacional, generación de contenido y data adaptadas a las necesidades de cada mercado y cliente. Contacta con nosotros y estaremos encantados de ayudarte.
¿Quieres más información sobre nuestros servicios de IA Generativa?
Contacta con nuestro equipo de expertos en IA Generativa