

Como ya sabrás existen diferentes modelos y tipos de bases de datos y algunos de ellos han crecido en popularidad en los últimos tiempos mientras que otros han ido perdiendo el interés de los usuarios. Es el caso, por ejemplo, de los modelos de bases de datos relacionales frente a las bases de datos NoSQL.
¿Qué son las bases de datos relacionales?
Las bases de datos relacionales son una forma de organizar y almacenar información en tablas que se parecen mucho a una hoja de cálculo. Cada tabla contiene datos sobre un tipo específico de información, por ejemplo, una tabla para clientes, otra para productos y otra para pedidos. Dentro de cada tabla, los datos están organizados en filas (cada fila representa un registro, como un cliente específico) y columnas (cada columna representa un dato específico, como el nombre o la dirección del cliente).
Lo que hace especial a este tipo de base de datos es que las tablas pueden estar conectadas entre sí por medio de relaciones. Por ejemplo, un pedido puede estar relacionado con un cliente mediante un campo en común, como el ID del cliente. Estas conexiones permiten consultar y combinar datos fácilmente sin necesidad de repetir la información. Las bases de datos relacionales usan un lenguaje llamado SQL (Structured Query Language) para buscar, agregar o modificar los datos. Son ampliamente utilizadas porque son claras, organizadas y permiten manejar grandes cantidades de información de forma eficiente.
Ventajas de las bases de datos relacionales
Las bases de datos relacionales tienen varias ventajas frente a otros modelos, especialmente cuando se trata de organizar y consultar datos estructurados:
- Estructura clara y coherente: Al usar tablas con filas y columnas, el modelo relacional es fácil de entender y organizar. Esto ayuda a mantener los datos bien ordenados y evita redundancias gracias a la posibilidad de relacionar diferentes tablas.
- Flexibilidad para hacer consultas: Con SQL, se pueden hacer búsquedas complejas y combinar datos de múltiples tablas de forma rápida y precisa. Esto no siempre es tan fácil en otros modelos como los basados en documentos o en grafos.
- Integridad y consistencia de los datos: Las bases relacionales permiten establecer reglas (como claves primarias y foráneas) que aseguran que los datos estén completos y conectados correctamente, reduciendo errores y duplicaciones.
- Amplio soporte y madurez: Este modelo lleva décadas en uso, por lo que existen muchas herramientas, documentación y profesionales capacitados. Además, los sistemas de gestión de bases de datos relacionales (como MySQL, PostgreSQL u Oracle) son muy estables y confiables.
Limitaciones de las bases de datos relacionales
Es conocido por todos que cada vez se generan más y más datos, y el escalado vertical (scale-up) que ofrecen las bases de datos relacionales, en principio, no parece una buena solución respecto al escalado horizontal (scale-out) de los entornos distribuidos de las principales bases de datos NoSQL.
Basándonos en esto y viendo que el incremento de volumen de datos avanza a una velocidad mayor que el incremento de capacidad del hardware, es normal pensar que tarde o temprano, las bases de datos relacionales se van a quedar cortas.
Para analizar cómo afrontan hoy en día y qué opciones de futuro planean las bases de datos relacionales respecto a estos problemas, vamos a diferenciar los dos tipos de entornos que principalmente existen.
Por un lado, tenemos entornos datawarehouse (DW), entornos analíticos donde la información se carga en batches y se transforma quedando generalmente estática para favorecer el reporting y explotación de la misma.
Por otro lado, tenemos los entornos transaccionales (OLTP), entornos operacionales donde la información está viva, y en los cuales se favorece el rendimiento de estas frecuentes modificaciones.
Entornos datawarehouse
Hoy en día, la apuesta en este tipo de entornos de las bases de datos relacionales es claramente el almacenamiento de la información de forma columnar.
A diferencia del almacenamiento tradicional de la información en este tipo de bases de datos en forma de registros, el almacenamiento de la información de cada columna de forma conjunta ofrece un ratio de compresión de tamaño de los datos superior al 80% en la mayoría de casos.
Debido a esta significativa compresión es más fácil mantener esos datos en memoria, añadido a la capacidad de procesar la información en batches de registros, ofrece un rendimiento muy competitivo sobre todo en consultas de agregación.
Tanto SQL Server, desde la versión 2012, como Oracle, desde la 12c, ofrecen sus tecnologías columnstore integradas en su propio motor de base de datos.
Basándose en esta tecnología, y hablando de cantidades ingentes de datos, no se quedan atrás y ofrecen soluciones en la nube distribuidas en entornos de procesamiento masivo en paralelo (MPP).
Respecto a SQL Server tenemos Azure SQL Data warehouse, anteriormente conocido como SQL Server Parallel Data Warehouse.
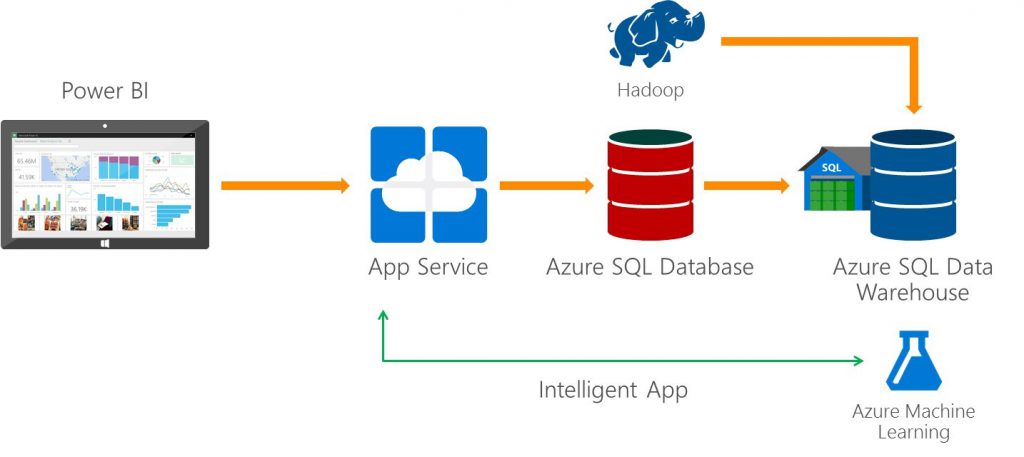
Gráfico sobre SQL Data Warehouse
Hablando de Oracle, han anunciado la versión para datawarehouses de su nueva base de datos Oracle 18c para Diciembre de 2017, distribuida y autónoma tanto en cloud privada como pública.

Información sobre la versión de de Oracle 18c .
Entornos transaccionales
En este tipo de entornos, tanto para relacionales como para NoSQL, el objetivo es claro, mantener los datos en memoria y evitar accesos a disco.
Debido a que, tanto la velocidad de acceso como de escritura es mucho mayor en memoria que en disco, el único uso de la memoria para realizar las operaciones en este tipo de entornos es crítica para el buen rendimiento de las mismas.
Hoy en día SQL Server, desde la versión 2014, ofrece su tecnología en memoria (In-Memory OLTP) integrada en el motor de base de datos.
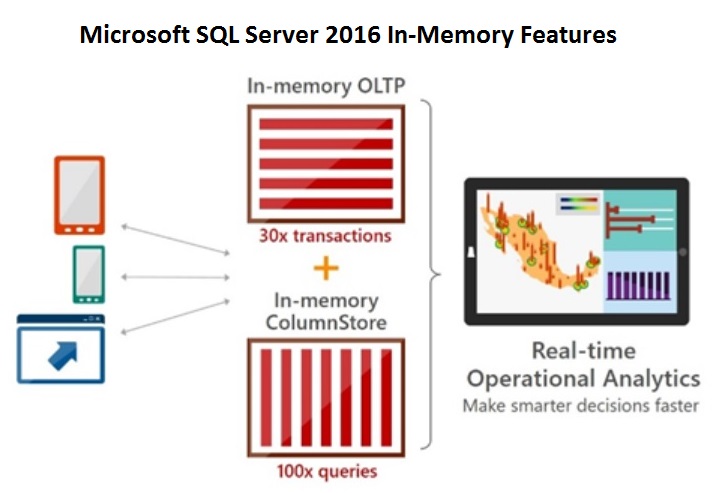
Característica In-Memory oltp de SQL Server extraído del blog DBA Consulting.
Respecto a Oracle, se puede aplicar su tecnología de almacenamiento columnar de la que hablábamos antes, ya que también reside en memoria, pero en entornos puramente OLTP se recomienda usar otro producto aparte llamado Oracle TimesTen.
Como opciones de futuro, Oracle ha anunciado la versión para entornos OLTP de su nueva base de datos Oracle 18c para Junio del 2018, distribuida y autónoma tanto en cloud privada como pública.
Respecto a SQL Server de momento no parece haber ninguna solución distribuida para este tipo de entornos, aunque viendo casos de uso en una sola máquina se han registrado 1.200.000 batches/seg, una cifra bastante aceptable para un entorno OLTP.
En este artículo hemos repasado las principales características existentes de las principales bases de datos relacionales para afrontar el constante incremento de volumen de datos que experimentamos. También hemos visto como afrontan su futuro apostando por entornos distribuidos y, claramente especializados en diferentes tipos de entornos, principalmente como soluciones en la nube.
¿Quieres más información? Contacta con Hiberus Tecnologías Diferenciales y estaremos encantados de ayudarte.
¿Quieres más información sobre nuestros servicios de Big Data?
Contacta con nuestro equipo de expertos en Data & Analytics
