

En la actualidad la transformación digital es una parte importante para la recolección y análisis de datos debido a la gran influencia del Big Data. Sin embargo el concepto de Data Warehouse existe desde hace unas cuantas décadas y continuamos utilizándolo hoy en día.
A lo largo de este artículo se van a describir las visiones más importantes que existen a la hora de diseñar un almacén de datos (Data Warehouse).
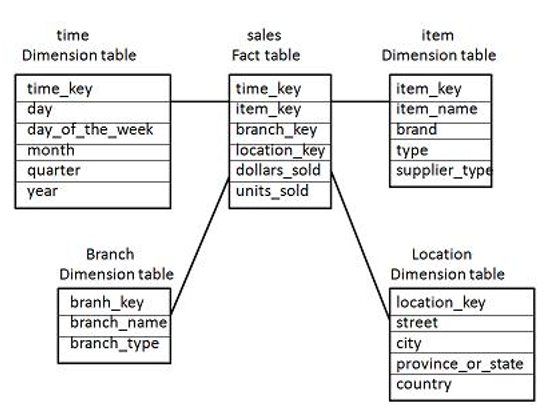
En primer lugar, sería conveniente explicar en qué consiste un almacén de datos. Un Data Warehouse se define como una colección de datos orientada a un determinado ámbito, integrado, no volátil y variable en el tiempo, que ayuda a la toma de decisiones en la entidad en la que se utiliza. En un almacén de datos se guardan grandes cantidades de datos provenientes de diferentes fuentes que deben de tener un formato coherente para su posterior explotación (análisis, reportes…) por parte de la organización que hace uso de él.
También es importante saber diferenciar un Data Warehouse de un Data Mart, mientras que el primero contiene todos los datos de una organización, un Data Mart solo contiene un subconjunto de ellos centrándose únicamente en un área de negocio. Ambos son dos componentes fundamentales en la arquitectura de los proyectos de Business Intelligence.
Una vez que ha quedado claro lo que es un Data Warehouse, pasamos a repasar las dos principales visiones de los que son considerados los padres de los almacenes de datos: Bill Inmon, que entiende un Data Warehouse como un almacén de datos único y global para toda la empresa, y Ralph Kimball, que prefiere construir pequeños modelos para ir evolucionando a modelos superiores.
Enfoque de Inmon
La visión de Inmon se caracteriza por tener un repositorio central de datos único. Este enfoque se basa en la metodología top-down, que es aquella que toma las decisiones partiendo de las variables más globales para ir descendiendo hasta las más específicas. Es decir, Inmon parte de la construcción de un almacén de datos global del que se irán nutriendo los diferentes Data Marts, evitando así las diferentes inconsistencias que puedan existir entre diferentes departamentos.
En cuanto a la estructura del Data Warehouse, Inmon defiende tener un modelo normalizado aplicando las 3 formas normales:
- Las tablas deberán de tener una clave primaria y sus atributos contener valores atómicos.
- Todos los atributos que no son clave primaria tienen dependencia funcional completa con respecto a todas las claves existentes en el esquema. Para recuperar un atributo no clave se necesita acceder por la clave completa, no por una subclave.
- Todos los atributos que no son clave primaria no dependen transitivamente de ésta.
La metodología de Kimball
La visión de Kimball difiere en todo con el enfoque de Inmon ya que apuesta por la metodología bottom-up y por una estructura desnormalizada.
La metodología bottom-up se define como el diseño en detalle de partes individuales para luego enlazarlas entre ellas para formar el sistema completo. Es decir, con la metodología de Kimball se van diseñando a medida, según las necesidades de los departamentos, los diferentes Data Marts, para unirlos y formar el Data Warehouse de la empresa.
La idea de Kimball comienza con la necesidad de un departamento de construir un Data Warehouse para unirlo a otros Data Marts de otros departamentos a medida que vayan apareciendo. Estos diferentes Data Marts deberán de mantener un mismo estándar y se deberán de hacer uso, en caso de necesitarlo, de las llamadas dimensiones conformadas, que son las dimensiones comunes que comparten los diferentes departamentos, para garantizar así la integridad del Data Warehouse. Estas dimensiones, deberán tener un diseño consistente apto para todos los Data Marts.
Los Data Marts estarán estructurados en modelos de datos dimensionales (estrella o copo de nieve) completamente desnormalizados, diseñados para la consulta.
Existen cuatro pasos básicos para el diseño de un Data Mart con la metodología de Kimball:
- Identificación del proceso de negocio.
- Establecer el nivel de granularidad más pequeño.
- Elegir las dimensiones y atributos.
- Identificar las métricas y los hechos.
Diferencias entre Kimball e Inmon ¿Cuál es mejor?
La mayor diferencia que existe entre uno y otro se comprueba en la metodología que se sigue para el diseño del almacén de datos, pues son totalmente opuestas una de la otra. La metodología que propone Inmon, top-down, se caracteriza por diseñar de arriba hacia abajo, de lo global a lo departamental. Mientras que con bottom-up, la metodología que sigue Kimball, se hace lo contrario, diseña cada departamento su propia estructura para conformar el Data Warehouse global.
En este sentido el enfoque de Inmon tiene la ventaja de que toda la empresa va a tener la misma estructura, mientras que para Kimball al tener varios Data Marts diferentes podrían diferir unos de otros en aspectos que podrían ser comunes. Por otro lado, la ventaja que tiene la metodología de Kimball es que cada departamento va a tener independencia a la hora de crear sus propios Data Marts, eso sí, siguiendo un estándar común, mientras que Kimball se tiene que amoldar a la estructura global.
La otra diferencia por considerar es la perteneciente a la estructura de los datos. Inmon apuesta por una estructura normalizada frente a la desnormalización de Kimball. La mayor ventaja de la normalización es que se evita la redundancia de los datos y se asegura que se mantiene la integridad referencial por lo que se facilita el mantenimiento de las tablas y se disminuye el tamaño de la base de datos. Por el contrario, el modelo dimensional que propone Kimball facilita la obtención de datos al necesitar queries menos complejas para obtener análisis e informes, ayudando al uso de herramientas de reporting.
A pesar de las diferencias las dos visiones tienen un mismo objetivo, tener un sistema de almacenamiento capaz de responder a todas las posibles respuestas que puedan surgir en la empresa. Por lo tanto, la elección de un enfoque u otro tendrá que hacerse en función de las necesidades que surjan. Si lo que se quiere es un sistema en el que se van a hacer análisis de datos diferenciando los diferentes departamentos de la compañía quizás lo ideal sería apostar por Kimball mientras que si se quiere tener una visión más global y se debe tener especial cuidado con la integridad de los datos, hay que decantarse con la visión de Inmon.
Además de todo esto, también es importante conocer tus recursos, pues la metodología de Inmon requerirá más presupuesto inicial frente a un coste más bajo en mantenimiento, y para Kimball todo lo contrario, un pequeño coste inicial frente a un gran coste de mantenimiento.
Alternativa
De estas dos técnicas, que son las más relevantes a fecha de hoy, nace un gran debate entre cuál es la mejor y aparece otra visión que hay que tener en cuenta. Dan Linstedt publica en el año 2000 los principios de Data Vault, que es una técnica híbrida entre el modelo normalizado y el modelo dimensional donde se toma lo mejor de cada una y se solucionan sus defectos. La definición que le da Dan Linstedt es la siguiente:
“Data Vault es un conjunto de tablas normalizadas orientadas al detalle, con seguimiento histórico y vinculadas de forma única, que dan soporte a una o más áreas funcionales del negocio. Se trata de un enfoque híbrido que engloba lo mejor de la tercera forma normal (3NF) y el esquema en estrella. El diseño es flexible, escalable, consistente y adaptable a las necesidades de la empresa. Se trata de un modelo de datos diseñado específicamente para satisfacer las necesidades de los almacenes de datos empresariales actuales.”
Data Vault se apoya en cuatro principios básicos:
- Trazabilidad: Se deberá de informar sobre el origen de datos y su fecha de carga para poder tener una trazabilidad.
- Todos los datos son importantes: Por lo que se ha de almacenar toda la información de origen, aunque no se necesite en la actualidad.
- Tolerancia al cambio: Será importante separar la información estructural de las descripciones para poder soportar diferentes cambios de negocio.
- Velocidad: Se debe garantizar la carga paralelizada de sus estructuras para obtener una buena velocidad de carga.
Todo ello hace una mejora notable frente a los sistemas tradicionales.
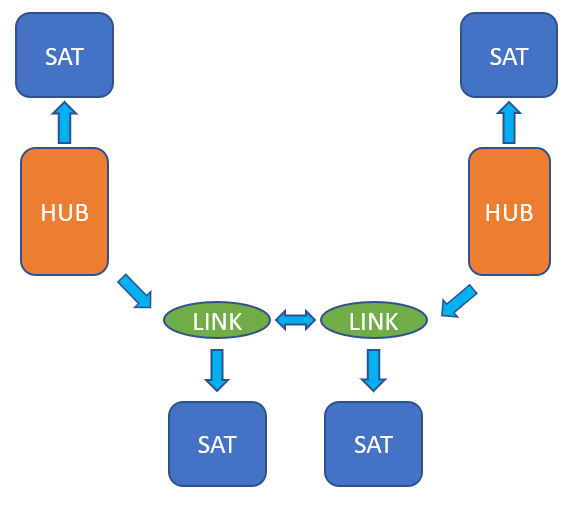
En cuanto a la estructura que define Dan Linstedt, se encuentran tres tipos de tablas:
- Hubs: Contienen listados con las claves de negocio.
- Links: Contienen las relaciones que existen entre las diferentes claves de negocio, es decir, entre los hubs. Cuando las relaciones de negocio cambien aparecerán nuevos links, lo que provee flexibilidad y escalabilidad al poder realizar cambios en el futuro sin necesidad de impactar en lo ya existente.
- Satellites: En estas tablas se guardan las descripciones tanto de las claves de negocio como de sus relaciones, por lo que los satellites se conectarán con los hub y con los links. Estas descripciones pueden cambiar con el tiempo y se tratarán como una SCD de tipo 2.
El modelo tiene diversas ventajas entre las que destacan:
- Facilidad de ampliación, que lo convierte en un modelo altamente escalables.
- Los procesos de carga se pueden paralelizar, por lo que es más veloz.
- Fácil auditoria.
Por otra parte su principal desventaja es que hay una gran cantidad de objetos, lo que provoca que haya que aplicar un mayor esfuerzo en la modelización.
Data Vault 2.0
Finalizamos señalando el nacimiento de un nuevo estándar a raíz de Data Vault, denominado Data Vault 2.0, que consta de tres pilares: metodología, arquitectura y modelo.
Dentro de la metodología se define la implementación de buenas prácticas incluyendo CMMI para mejora continua, TQM para calidad de la información, PMP para control de proyectos, Scrum para desarrollo ágil y SDLC como ciclos de desarrollo.
También Data Vault 2.0 se centra en la inclusión de nuevos componentes como Big Data, NoSQL… centrándose también en el rendimiento del modelo.
Hiberus cuenta con una unidad especializada en servicios de Data & Analytics desde donde ofrecemos soluciones integrales de consultoría estadística y análisis de datos con especialización por áreas de conocimiento, donde se acompaña a nuestros clientes en cada proyecto integrándonos como parte de su equipo. Ponte en contacto con nosotros y estaremos encantados de ayudarte.

¿Quieres más información sobre nuestros servicios de Data & Analytics?
Contacta con nuestro equipo de expertos en Data & Analytics
