

Las variables de ODI (Oracle Data Integrator) se utilizan para manejar parámetros ETL (extracción, carga y transformación). Se trata de una característica muy importante que es necesario entender para poder usarla de forma efectiva. En este post te contamos cómo aplicar las variables de ODI en el procesamiento de ficheros.
¿Qué es Oracle Data Integrator?
Antes de abordar el tema que nos ocupa, empecemos por el principio: ¿qué es ODI? Oracle Data Integrator es una plataforma de integración completa creada por Oracle que cubre todos los requisitos de integración de datos: extracción, carga y transformación (ETL). Permite combinar datos de distintas fuentes para que el usuario tenga una visión unificada de todos sus datos.
Cubre diferentes necesidades empresariales en relación con la integración de datos:
- Data Warehousing e Inteligencia de Negocios. Tiene la capacidad de manejar volúmenes grandes de datos con un desempeño óptimo, así como cargas incrementales, integridad de datos, reglas de negocio y consistencia.
- Arquitectura orientada a servicios. Permite invocar servicios externos para la integración e implementar servicios de integración y transformación que se integran a una arquitectura orientada a servicios.
- Master Data Management. Consolida, limpia, mejora y sincroniza los datos maestros con aplicaciones, procesos de negocio y herramientas analíticas.
- Migración. Provee cargas masivas de datos históricos, incluyendo complejas transformaciones de sistemas legacy a nuevos sistemas.
¿Qué son las variables de ODI?
Las variables de ODI son objetos que almacenan un solo valor, ya sea una cadena, un número o una fecha, de dos maneras principalmente:
- Asignación directa de un valor
- Utilización de una sentencia SQL para obtener el valor a asignar
Una variable se puede crear como una variable global o en un proyecto, un factor que determina el alcance de la misma. Las variables globales se pueden utilizar en todos los proyectos, mientras que las variables de proyecto solo se pueden usar en el proyecto en el que se definen.
¿Cómo funciona ODI?
ODI presenta un entorno gráfico para construir, gestionar y mantener procesos de integración de datos desde distintos orígenes a distintos destinos, que generalmente son entornos de Data Warehouse.
Todas las fuentes y destinos de datos utilizados en ODI (tablas, ficheros, etc..), independientemente de la tecnología utilizada, son modelados en estructuras denominadas almacenes de datos (datastores). Los datastores, a su vez, se agrupan en modelos dependiendo de la tecnología utilizada.
De esta forma, se puede crear tanto un modelo para tecnología Oracle, en el cual se agruparán los datastores de tipo tabla de una determinada conexión de base de datos, como un modelo para tecnología File donde agrupar los datastores de tipo fichero de un determinado servidor.
Estos modelos se independizan de las bases de datos y sistemas de ficheros donde se va a desplegar el proceso de integración mediante la denominada topología.
Los procesos de integración en ODI que utilizan los datastores como orígenes y destinos son realizados mediante otro tipo de objeto denominado asignación (mapping).
El proceso completo de integración que engloba el uso de variables, mappings, procedimientos, etc., es llevado a cabo por otro tipo de objeto denominado paquete (package), que en su versión compilada recibe el nombre de caso o escenario. A su vez, los paquetes pueden llamar a otros paquetes, generando un flujo de integración de un elevado nivel de complejidad para satisfacer cualquier necesidad.
¿Cómo aplicar las variables de ODI para gestionar el uso de ficheros?
De manera bastante habitual, se suele utilizar un datastore de tipo fichero en ODI indicando de manera estática la ruta absoluta y el nombre de fichero dentro del sistema de ficheros donde reside.
Esta metodología genera dependencia y obliga a respetar esta configuración de directorios y nombres en los distintos entornos donde se despliegue el proceso de integración realizado con ODI.
Cualquier cambio de ruta o nombre de fichero implicaría modificar el desarrollo y volver a desplegar en los distintos entornos.
Para subsanar esta situación y dar flexibilidad e independencia a los desarrollos donde se utilizan ficheros, vamos a mostrar una metodología aplicando las variables de ODI a dichos objetos. Utilizaremos como ejemplo un proceso de ODI que realiza una integración de datos, transfiriendo el contenido de una tabla a un fichero con extensión csv.
Creación de tabla ejemplo en base de datos
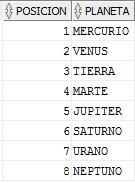
Creamos una tabla ejemplo en base de datos Oracle que contiene los planetas del sistema solar y su orden de posición respecto al Sol (T_DEMO_FICHERO)
Definición de un nuevo modelo de datos
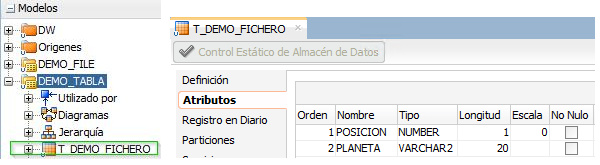
Definimos un nuevo modelo de datos de Oracle (DEMO_TABLA) enlazado a la base de datos. Dentro creamos el datastore de tipo tabla T_DEMO_FICHERO con la estructura de la tabla creada anteriormente.
Definición de un nuevo modelo de datos tipo FILE
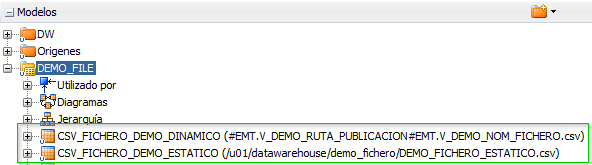
Definimos un nuevo modelo de datos tipo FILE (DEMO_FILE). Dentro creamos dos datastores de tipo fichero con la estructura adecuada al fichero que va a recibir los datos:
- CSV_FICHERO_DEMO_DINAMICO
- CSV_FICHERO_DEMO_ESTATICO
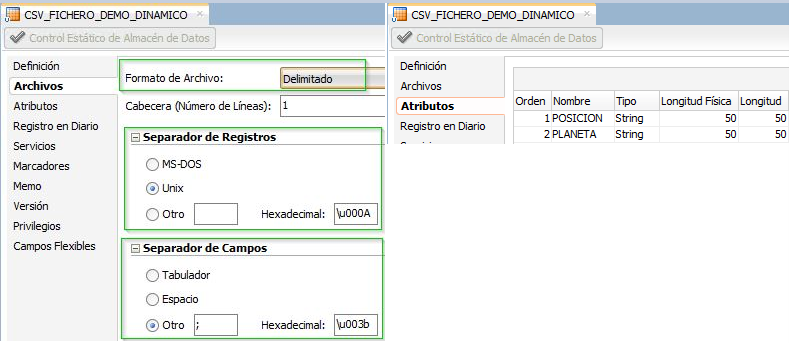
En el datastore CSV_FICHERO_DEMO_ESTATICO el nombre de recurso está definido por una ruta de directorios y un nombre de fichero de manera fija (/u01/datawarehouse/demo_fichero/DEMO_FICHERO_ESTATICO.csv).
En el datastore CSV_FICHERO_DEMO_DINAMICO el nombre de recurso está definido de manera dinámica por una variable que determina su ruta dentro del sistema de ficheros (V_DEMO_RUTA_PUBLICACION), una variable que establece el nombre de fichero (V_DEMO_NOM_FICHERO) y una extensión (en este caso .csv).
A continuación, se detallan otras propiedades a destacar en los datastores tipo file, como el tipo de fichero (longitud fija o delimitado) el formato de fin de línea, el carácter separador de los campos y los campos que conforman los ficheros del ejemplo.
Las dos variables de tipo alfanumérico utilizadas por el datastore han sido creadas y están definidas de la siguiente manera:
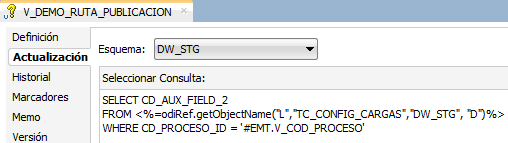
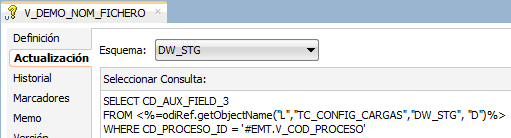
Estas variables tienen definida internamente una consulta a una tabla de configuración almacenada en la base de datos Oracle para obtener sus valores dado un determinado código de proceso.
Definición de un registro en la tabla de configuración
Para el ejemplo, se ha definido un registro en la tabla de configuración cuyo código de proceso se denomina “DEMO_FICHERO”, informando los campos asociados a las variables (CD_AUX_FIELD_2 y CD_AUX_FIELD_3) con los valores de ruta y nombre de fichero respectivamente.
![]()
Definición de un paquete para el flujo completo de integración
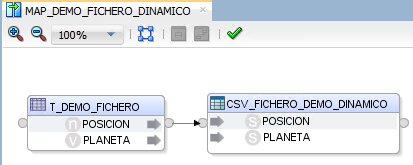
El paquete definido para realizar el flujo completo de integración que dará lugar a la generación del fichero de manera dinámica es el siguiente:


En primer lugar, se asigna a la variable V_COD_PROCESO el valor ‘DEMO_FICHERO’ como código de proceso.
A continuación, las variables V_DEMO_RUTA_PUBLICACION y V_DEMO_NOM_FICHERO obtienen sus respectivos valores de ruta y nombre mediante consulta de la tabla de configuración para el citado proceso.
Finalmente se ejecuta el mapping MAP_DEMO_FICHERO_DINAMICO, informando el datastore CSV_FICHERO_DEMO_DINAMICO a partir de la tabla T_DEMO_FICHERO y aplicando la ruta y el nombre definidos en las variables para generar el fichero.
Accedemos al servidor y comprobamos que el fichero ha sido creado en la ruta adecuada con el nombre adecuado.
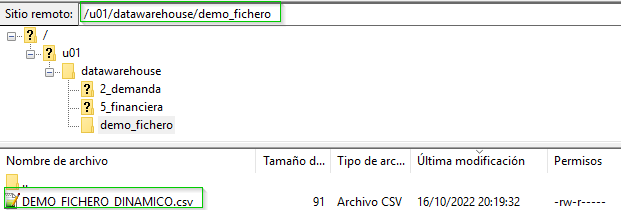
Si por necesidades de proyecto se requiriera cambiar la ubicación del fichero o su nombre, bastaría con modificar los valores en el registro de la tabla de configuración para el citado proceso.
Para comprobarlo se va a modificar la ruta y nombre del fichero en el registro de base de datos.
![]()
Volvemos a ejecutar el paquete y comprobamos que el fichero se ha generado en la nueva ruta con el nuevo nombre.
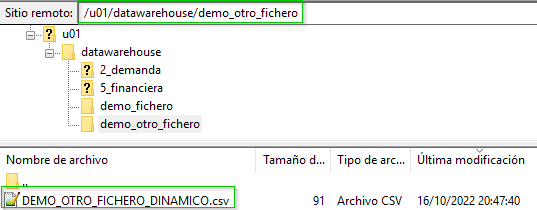
Si se hubiese utilizado en el proceso de integración el datastore CSV_FICHERO_DEMO_ESTATICO, el fichero siempre se generaría en la misma ruta y con el mismo nombre.
Resultados del proceso
Como se observa, esta técnica permite una flexibilidad total en el uso de ficheros y libera de mantenimientos a los desarrollos que los utilizan, implicando tan solo una actualización de valores por base de datos.
Esta metodología puede ampliar todavía más la funcionalidad añadiendo otras variables o modificando las existentes. Un posible ejemplo práctico sería añadir la fecha de generación en formato AAAAMMDD al final del nombre del fichero o un valor incremental en el caso de generar ficheros consecutivos por lotes, etc.
El límite está en la imaginación…
Hiberus cuenta entre sus tecnologías diferenciales con una unidad especializada en servicios de Data & Analytics formada por un equipo de profesionales comprometidos, responsables, cercanos, especializados y competitivos con amplio expertise en tecnología, análisis de datos e innovación. Desde esta unidad se ofrecen soluciones integrales de consultoría estadística y análisis de datos con especialización por áreas de conocimiento, donde se acompaña a nuestros clientes en cada proyecto integrándonos como parte de su equipo. Contacta con nosotros para más información.
¿Quieres más información sobre nuestros servicios de Data & Analytics?
Contacta con nuestro equipo de expertos en Data & Analytics
