

Junto al Grupo Henneo, dentro de su departamento de TI y en colaboración con Departamento de Informática e Ingeniería de Sistemas de la Universidad de Zaragoza, hemos desarrollado un novedoso sistema de reconocimiento y desambiguación de entidades.
Qué es una entidad
Entendemos por “entidad” todas aquellas personas, lugares, organizaciones o temas que tienen identidad propia y única. A todas las palabras que pueden ser usadas para referirnos a estar entidades, las llamamos “named entity”. Por ejemplo, la entidad “San Sebastián”, puede aparecer en los textos referenciada con las siguientes “named entites”: San Sebastián, Donostia, Donosti, La Bella Easo, Irutxulo…
Este sistema de desambiguación se ha integrado dentro de EMMA, Entorno MultiMedia de Archivo, Plataforma de gestión documental desarrollada en el Departamento de Informática del Grupo Heraldo junto al equipo de soporte de Hiberus.
Su principal misión es facilitar a documentalistas y periodistas el acceso a todas las noticias publicadas en el medio de comunicación de manera ágil y flexible. EMMA almacena todos las fotografías y las noticias publicadas y todas las páginas de la edición impresa, tanto de Heraldo de Aragón como de otros medios de comunicación del Grupo Heraldo. Permite desde la sencilla navegación entre las páginas de un periódico hasta realizar búsquedas profesionales. Este buscador web es una de las principales herramientas de trabajo para el Departamento de Documentación.
Funcionamiento del sistema de desambiguación de entidades
Este sistema de desambiguación de entidades contribuye a obtener y mantener un catálogo de entidades completo y actualizado. Otros procesos de la plataforma se han beneficiado de toda la información recopilada en este catálogo, en especial, se han mejorado los procesos de extracción de información desde el archivo local, se ha realizado la categorización automática de las noticias, enlazando cada texto publicado con las entidades que aparecen en él y se ha mejorado el sistema de generación de infoboxes con información relevante sobre cada entidad, ya que utiliza como soporte este catálogo de entidades generado.
Esto permite, por ejemplo, realizar búsquedas sobre las entidades que aparecen referenciadas en las noticias.
Funcionamiento del sistema
El flujo completo de trabajo del sistema se puede ver en la siguiente imagen:
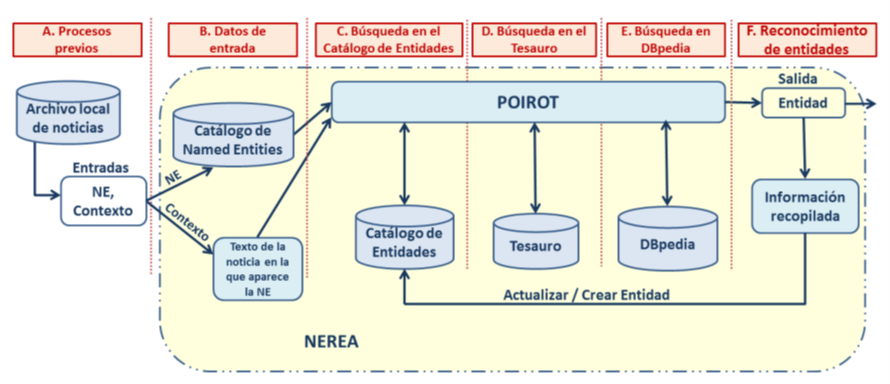
Procesos previos
El sistema tiene algunos procesos auxiliares que extraen y calculan información importante del archivo local de noticias para su posterior utilización:
-
- Servicio lematizador: para cada texto del archivo de noticias, calcula la forma canónica o lema de cada palabra. Este proceso es muy útil para lenguajes como el castellano, con declinaciones y gran cantidad de formas verbales.
- Servicio TDF: recorre todos los textos lematizados por el anterior servicio y calcula, el número de apariciones de cada palabra. Esto es necesario para que el siguiente servicio de extracción de palabras clave pueda obtener la _puntuación_ de cada palabra clave según los algoritmos TF-WP, Term Frequence Word Position y TF-IDF, Term Frequency, Inverse Document Frequency.
- Servicio de extracción de palabras clave: Escoge las palabras más relevantes de cada texto y extrae además todas las “named entities”, referencias a entidades, que hay en cada noticia y guarda también la estadística de apariciones de cada “named entity”.
Datos de entrada
El sistema de desambiguación recibe como datos de entrada una “named entity” y su contexto, es decir, todo el texto de la noticia en la que ha aparecido. Con ese texto, se construye un vector de contexto. Para cada “named entity”, se busca toda la información relacionada en las bases de conocimiento locales y globales, tesauro y DBpedia respectivamente. En cada una de estas fuentes de información, el sistema intenta localizar todos los posibles candidatos que coincidan con la entidad mencionada, y se crea una lista de candidatos. Cada uno de los candidatos se identifica según su origen: descriptores del tesauro en el caso local y URLs globales en el caso de DBpedia.
Búsqueda en el catálogo de entidades
Se obtienen todas las entidades que tienen a la “named entity” asociada en el catálogo de entidades. Para cada una de estas entidades, genera un vector de contexto según las palabras clave que tiene asociadas cada entidad. Después, se compara mediante la fórmula de similitud del coseno cada uno de esos vectores de contexto de las entidades candidatas con el que se ha generado para el texto de la noticia. La entidad con la mayor similitud será seleccionada, siempre que su similitud supere el umbral establecido. En caso de que ninguna supere el umbral, el proceso continuará en el paso siguiente.
Búsqueda en el tesauro
Igual que en el paso anterior, para cada descriptor de tesauro recopilado como posible candidato en el momento de almacenar esa “named entity”, busca en el archivo de noticias los textos más relevantes y genera un vector de contexto con esos textos. De manera análoga al paso anterior, si se ha seleccionado un descriptor, se busca si hay alguna entidad en el catálogo de entidades con ese descriptor asociado. Si la hay, devuelve esa entidad y actualiza su lista de palabras clave, si no la hay, continúa en el siguiente paso, guardando el descriptor de tesauro para asignarlo a la entidad en caso de que se localice en el siguiente paso.
Búsqueda en DBpedia
A la lista de candidatos de DBpedia se le añade las URLs asociadas a esa “named entity” en la colección “pairCounts” extraída de DBpedia Spotlight. Además, el sistema se beneficia de la información contenida en las páginas de desambiguación de DBpedia: si el sistema detecta que alguna de las URLs candidatas es una página de desambiguación4, el sistema recoge todas las URLs contenidos en esa página, y las añade al conjunto de candidatas. Para cada URL candidata, se obtiene el cuerpo de la página de DBpedia, extrae la información, genera un vector de contexto y elige la de mayor similitud si supera el umbral establecido. Si se ha seccionado una URL, el sistema de desambiguación comprueba si alguna entidad del catálogo tiene esa URL asociada, si es así, devuelve esa entidad y actualiza su lista de palabras clave.
Reconocimiento de Entidades
En este punto, hay dos escenarios posibles:
- Se ha seleccionado una entidad del catálogo: En este caso, el registro correspondiente a esa entidad se actualizará con toda la información obtenida.
- No se ha seleccionado ninguna entidad: Si se ha seleccionado algún identificador local o global, se creará una entidad en el catálogo de entidades. Si no se ha seleccionado ningún identificador, se asume que ha ocurrido un falso positivo. En estos casos, se descartará la “named entity”.
Evaluación del sistema de reconocimiento y desambiguación de entidades
El sistema resultante fue evaluado antes de su puesta en marcha en dos escenarios diferentes:
Escenario 1
Con un conjunto de datos de prueba público, en inglés, conocido como OKE 2015, que contiene 196 frases extraídas de artículos de Wikipedia y que nos permite comparar el comportamiento de nuestro sistema con otros que han sido probados con este mismo conjunto de datos de evaluación. Este conjunto de datos es un conjunto de datos de prueba público, en inglés, que se publica durante el Open Knowledge Extraction Challenge; una prueba que se celebra cada año dentro de la conferencia European Semantic Web Conference (ESWC). Sirve para evaluar y comparar los sistemas de extracción de información que participan en el evento.
Los resultados obtenidos con este sistema en el escenario 1 son realmente satisfactorios, debido a la alta precisión obtenida por el sistema de desambiguación, superando incluso al resto de sistemas de desambiguación que han sido probados con el mismo conjunto de datos de evaluación en inglés como se puede ver en la siguiente tabla:
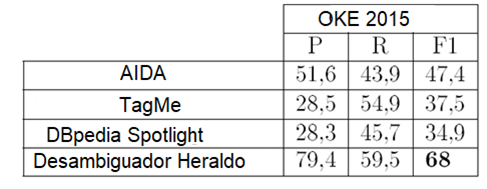
Los resultados de la tabla anterior se expresan en términos de Precisión (P), Recall (R) y F-measure (F1). Para los problemas de Extracción de Información como el que nos ocupa, estos parámetros se calculan como:
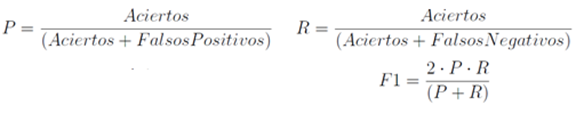
Escenario 2
Con un extracto del archivo de noticias local de Heraldo de Aragón, seleccionando explícitamente textos que contenían referencias a entidades ambiguas.
Para probar el sistema de desambiguación en su entorno real de trabajo y en idioma castellano, se generó un conjunto de datos de prueba local de la siguiente forma: selecciona un conjunto de “named entities” ambiguas y se seleccionaron al azar 500 noticias en las que aparecían. Todas las “named entities” presentes en esas noticias fueron desambiguadas por nuestro sistema. Para comprobar su correcto funcionamiento, personas del departamento de documentación anotaron manualmente a qué entidad hacía referencia cada una de esas named entities, y se calculó la precisión, Recall y F-measure del sistema en este escenario. Además, hemos comparado los resultados obtenidos por nuestro sistema realizando el proceso completo de desambiguación, es decir, búsqueda en el catálogo de entidades, búsqueda en el tesauro y búsqueda en DBpedia, con los que obtendría sólo con la etapa de búsqueda en DBpedia.
Con esta colección, para entidades conocidas a nivel global se obtiene un buen comportamiento, pero no ocurre igual para personajes y lugares locales. Como se puede comprobar en la siguiente tabla, la exactitud del proceso de desambiguación con nuestro sistema al completo es mejor que con una base de conocimiento global.

Evaluación de resultados
En ambos casos, el rendimiento de nuestro sistema obtiene mejores resultados para el conjunto de datos de evaluación considerado, que los sistemas anteriores de desambiguación de entidades publicados.
Tras los experimentos realizados tanto en inglés como en castellano, podemos inferir que el funcionamiento del sistema será correcto en otros idiomas soportados por Freeling, como francés, alemán o italiano, aunque todavía no se ha probado por no disponer de conjuntos de datos de prueba en estos idiomas.
La implementación de este sistema dio lugar a la publicación de un artículo científico de manera conjunta entre el Departamento de IT de Grupo Henneo y el Departamento de Informática e Ingeniería de Sistemas de la Universidad de Zaragoza. Este artículo científico lleva por título: “NEREA: Named Entity Recognition and Disambiguation Exploiting Local Document Repositories”. Este artículo se presentó en la conferencia ICTAI 2016: “28th IEEE International Conference on Tools with Artificial Intelligence”.
¿Quieres más información sobre nuestro servicio de desarrollo y outsourcing?
Contacta con nuestro equipo
