

Vivimos en la era del Big Data, donde la explotación de todo tipo de datos de las empresas se ha convertido en un objetivo cada vez más importante de cara a conocer mejor sus procesos de negocio y a optimizar sus beneficios.
Por ello, nace la necesidad de herramientas que se encarguen de gestionar todo el flujo de extracción y manipulación de los datos, adecuándose a unos patrones, criterios y necesidades específicas.
Una de las herramientas clave en este tipo de trabajos es Apache Airflow, una plataforma de código abierto nacida en 2015 con el fin de crear, planificar y monitorizar flujos de trabajo en lote.
¿Por qué Apache Airflow?
Algo que distingue a Apache Airflow de muchos de sus competidores es que todo el proceso de creación y planificación de sus flujos de trabajo se realiza de manera programática usando Python como lenguaje de programación.
Desde hace unos años Python ha ganado un gran prestigio gracias a la potencia y flexibilidad que ofrece, además de ser un lenguaje de código abierto y fácil de aprender, lo que hace a Apache Airflow una herramienta muy atractiva.
En contraposición con otras tecnologías de este tipo, como Apache NiFi, cuya metodología de trabajo consiste en una interfaz con la que puedes crear flujos de trabajo mediante “drag and drop” donde hay múltiples elementos que realizan funciones específicas, en Apache Airflow esto se hace 100% mediante scripts de código Python.
Esto les da una libertad y facilidad mucho más amplia a los programadores para crear procesos mucho más personalizados (cuya única frontera está en lo que te posibilite programar Python), sin limitarse a las acciones específicas que te permita realizar los elementos de la herramienta en cuestión.
¿Cómo funciona Apache Airflow?
Airflow trabaja con DAGs (Directed Aciclic Graph) como metodología para estructurar los procesos por lotes que se van a ejecutar en un flujo de trabajo mediante relaciones y dependencias. Estos grafos deben cumplir dos condiciones:
- Acíclicos: No puede haber bucles, por lo que la ejecución de un nodo no puede regresar a otro nodo que ya ha sido ejecutado.
- Dirigidos: Las relaciones de los nodos son de un único sentido.
Cada nodo de un DAG consiste en una función de Python que ejecuta una tarea específica. Además, existen multitud de elementos que simplifican el código considerablemente y facilitan aún más la programación de cada uno de estos nodos. Estos elementos se pueden clasificar en los siguientes tipos:
- Operators: Elementos que realizan una funcionalidad específica, cada nodo constará de un operator específico. Por ejemplo, MySql Operator ejecutará una sentencia SQL, o Bash Operator ejecutará un comando bash.
- Hooks: Interfaces que encapsulan las interacciones con una API. Puede entenderse como librerías propias que contienen funciones que interactúan con una API externa en concreto, y que suelen usarse dentro de los operators. Por ejemplo, Oracle Hook nos facilitará funciones para conectarnos a una base de datos, o para obtener los resultados de una query en concreto.
- xCom: Es una herramienta que permite compartir información entre nodos. Por defecto, los nodos de un DAG no transmiten información de uno a otro, pero en algún caso concreto puede ser necesario que un nodo necesite cierta información de alguno de sus predecesores, lo que soluciona xCom. Está pensado para transmitir una cantidad de datos pequeña.
Cabe añadir que si nos encontramos frente a un caso de uso recurrente para el cuál ningún operator o hook nos soluciona el problema, tenemos la posibilidad de crear los nuestros propios. Por ejemplo, si necesitamos una tarea que recolecte una serie de datos ubicados en HDFS y guardarlos en un contenedor S3, podemos programar nuestro propio operator “HDFStoS3”.
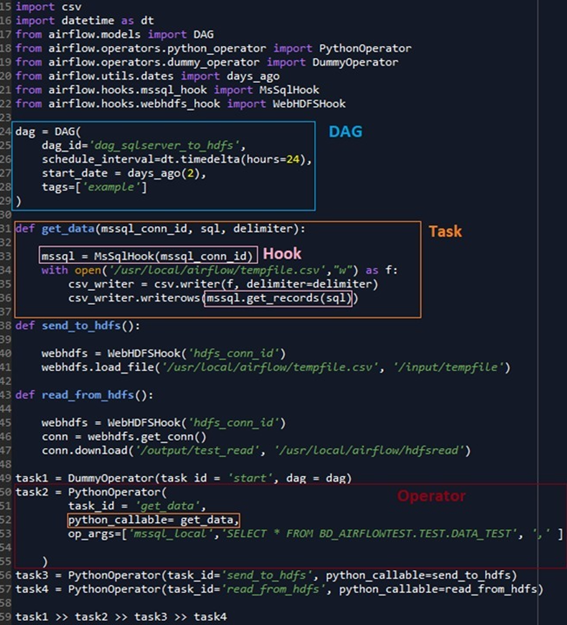
En la siguiente imagen podemos ver un ejemplo de un DAG, con cada uno de los elementos que lo componen:
Arquitectura de Airflow
La siguiente imagen resume como es la arquitectura de Apache Airflow, la cual está también diseñada usando únicamente Python.
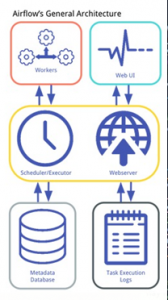
Una base de datos de metadatos contiene toda la información de los workflows, sus estados y sus dependencias. Esto está conectado con el scheduler, un proceso que en función de los datos de la base de datos, determina el orden en el que se ejecutara cada tarea y su prioridad. Muy ligado a éste tenemos el executor, que es un proceso de mensajería de colas que determinará que nodo ejecutará cada tarea. Es decir, el scheduler determina el orden de las tareas y el executor quién ejecutara cada una. Y por último tenemos los workers, procesos que ejecutan la lógica de una tarea.
Luego por otro lado tenemos un servidor web que utiliza la información de la base de datos y los logs generados por los workers para reflejar toda esta información en su interfaz web.
Uno de los elementos que más va a influir en el rendimiento de un DAG es el executor. Hay multitud de tipos, a continuación de resumen los 4 más utilizados:
- SequentialExecutor: Es el más sencillo, ejecuta las tareas en serie y en local.
- LocalExecutor: Muy parecido al anterior, también se ejecuta en local, pero éste permite paralelización.
- CeleryExecutor: Permite la ejecución de tareas distribuidas utilizando Celery, un módulo de Python utilizado para la gestión de tareas asíncronas y distribuidas. Para este executor ya es necesario una configuración extra, se necesita un sistema de mensajería de colas y, además, tener cada uno de los nodos distribuidos configurado de manera que se puedan ejecutar correctamente las tareas pertinentes.
- KubernetesExecutor: Permite la ejecución de tareas haciendo uso de pods de Kubernetes. En este caso el executor interacciona con la API de Kubernetes, y es esta la que se encarga de desplegar un pod para cada una de las tareas, con las características necesarias, y una vez acabado lo destruye e informa al executor del estado final de la tarea.
Interfaz de Airflow
Apache Airflow ofrece una interfaz de usuario muy completa donde nos permite monitorizar todos nuestros DAGs, ver sus estadísticas de ejecución y gestionar algunos elementos como las conexiones externas (Oracle, HIve, S3) de una manera muy intuitiva. Desde esta interfaz no se pueden crear ni modificar DAGs, está pensada únicamente para la monitorización de éstos.
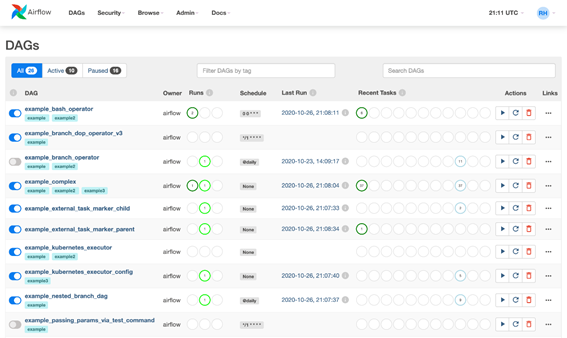
Como se puede observar en la imagen, vemos de una manera muy intuitiva como está planificado cada DAG, cuantas veces se ha ejecutado, ha fallado o si está actualmente en ejecución.
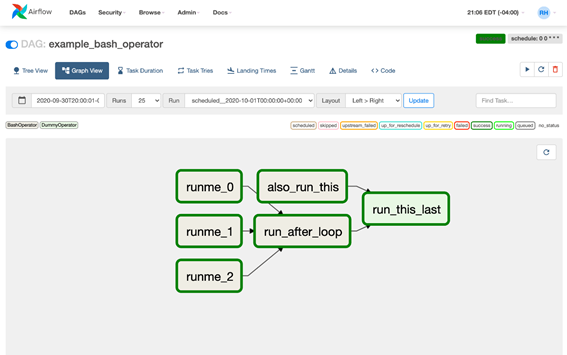
También nos permite ver la estructura de cada DAG en particular, y monitorizar el estado de cada nodo, además de poder revisar los logs de cada instancia de ejecución en caso de fallo.
Apache Airflow nos permite a los Data Engineers y Data Scientists crear complejos flujos de datos para todo tipo de casos de uso específicos (desde integración de datos en datalakes hasta definición y puesta en producción de pipelines de Machine Learning).
En Hiberus estamos haciendo uso de esta herramienta en proyectos como INAEM y Open Data Aragón. En el proyecto INAEM se hace uso de Airflow para la descarga y almacenamiento de ofertas laborales de diferentes plataformas y, además, para el reentrenamiento de modelos de Machine Learning para clasificar las ofertas de trabajo de manera periódica con nuevos datos.
Por otra parte, en el proyecto de Open Data Aragón se utiliza para la ingesta y extracción de información de artículos de los boletines oficiales (BOE, BOA, BOPH, BOPZ y BOPT).
En Hiberus contamos con un área específica de Data & Analytics formada por un equipo de profesionales con amplio expertise en en tecnología, análisis de datos e innovación. Somos expertos en Big Data, Machine Learning, Business Intelligence 2.0, y Business Intelligence y Analytics tradicional.
Descubre todo lo que podemos hacer por ti.
¿Quieres más información sobre nuestros servicios de Data & Analytics?
Contacta con nuestro equipo de expertos en Data & Analytics

Buenas Carlos, muy didactico y facil de leer , me ha quedado claro los componente de Apache Airflow. Una pregunta, en tu opinion Airflow puede ser una alternativa a BMC Control-M? como se comporta Airflow con los sistemas Legacy? es facil ejecutar por ejemplo PL/SQL?